Содержание
- 1 Данные
- 2 Как используется SQL и в чём его польза?
- 3 Теперь про базы
- 4 Вернёмся к SQL
- 5 Области применения и где используется SQL:
- 6 Виды СУБД
- 7 Сервер базы данных
- 8 Оперативная память сервера баз данных
- 9 Microsoft SQL Server
- 10 История
- 11 Функциональность
- 12 Разработка приложений
- 13 SQL Server Express Edition
- 14 Особенности линейки B
Данные
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу. Представим, что у нас есть каталог мебельного магазина. Нам нужно сохранить все данные из раздела «Шкафы» этого каталога в таблицу. Мы решили, что все шкафы отличаются друг от друга характеристиками:
- название производителя;
- название модели;
- высота;
- длина;
- цвет;
- количество дверей.
Составим таблицу и вобьём в неё выдуманные данные.
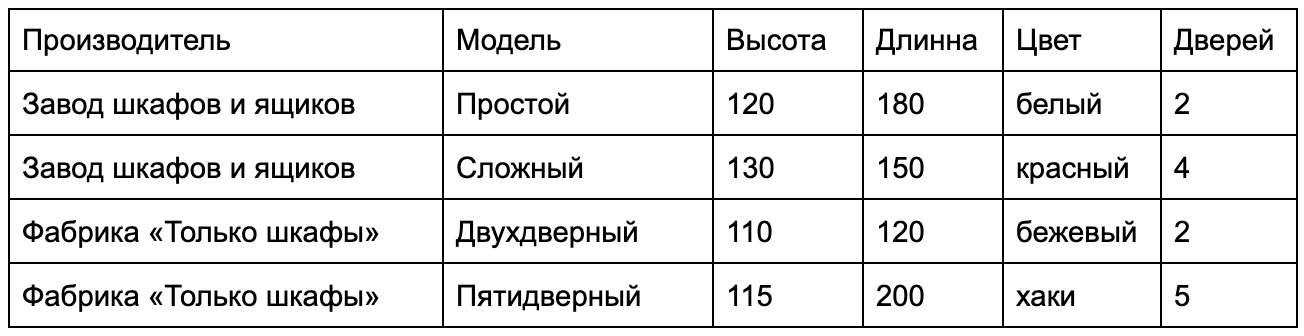
У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться. В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Как используется SQL и в чём его польза?
С 1974 года, когда язык структурированных запросов только появился, он обеспечивает взаимодейтсвие с системами управления базами данных (СУБД) во всём мире.
SQL, как простой и лёгкий в изучении язык из области свободного программного обеспечения, сегодня активно применяется:
- разработчиками баз данных (обеспечивают функциональность приложений),
- тестировщиками (в ручном и автоматическом режиме),
- администраторами (выполняют поддержание работоспособности среды).
Язык универсален и обладает чётко определённой структурой за счёт устоявшихся стандартов. Взаимодействие с базами данных происходит быстро даже в ситуациях, когда объёмы данных велики (Big Data). Кроме того, эффективное управление возможно даже без особых познаний кода.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки. В статье мы рассмотрим базы, которые состоят из таблиц, а инструментом манипулирования данными будет язык SQL.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».
Таблица «Производитель»:

Теперь таблицу «Каталог» можно оформить в другом виде:
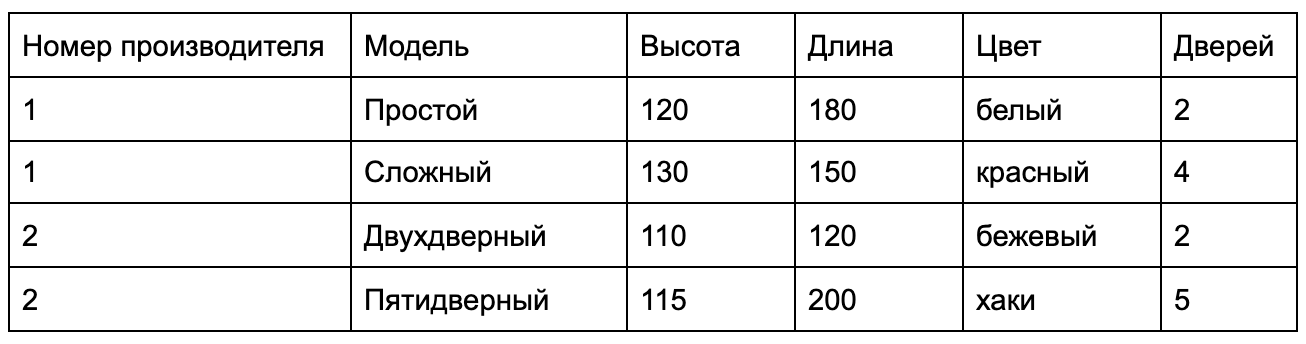
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
- Избавились от избыточных данных. Каталог стал занимать меньше места. Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель».
- Снизили вероятность ошибиться. При смене названия производителя нам достаточно отредактировать строку в таблице «Производитель», «Каталог» останется без изменений.
Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL. Как в любом другом языке программирования, в SQL есть операторы для работы с данными, из которых складываются команды. Операторы распределены по четырём языкам:
- DDL — Data Definition Language;
- DML — Data Manipulation Language;
- DCL — Data Control Language;
- TCL — Transaction Control Language.
Области применения и где используется SQL:
DDL
DDL (Data Definition Language, язык описания данных) — язык, включающий операторы для работы со структурой данных. Операторы DDL нужны для реализации этих возможностей:
- Создание объектов базы данных (таблиц, схем). Оператор: CREATE.
- Удаление объектов базы данных. Оператор: DROP.
- Изменение объектов базы данных. Оператор: ALTER.
DDL используется, когда нужно создать структуру для хранения данных. Он не отвечает за сами данные — только за то, как они будут разделены по таблицам и схемам.
DML
DML (Data Manipulation Language, язык манипуляции данными) — язык, который нужен для добавления, удаления, изменения данных и для выборки их из базы. Иными словами, для манипулирования данными. Пройдёмся по операторам:
- Оператор SELECT позволяет выбрать данные.
- Оператор INSERT — добавить новые.
- Оператор UPDATE — изменить существующие.
- Оператор DELETE — удалить.
DCL
DCL (Data Control Language, язык управления доступом к данным) — набор операторов, необходимых для предоставления доступа к данным. Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
- GRANT — оператор предоставления пользователю или группе набор каких-либо разрешений;
- REVOKE — оператор отзыва разрешений;
- DENY — задаёт запрет. Приоритет оператора DENY выше, чем у разрешения, выданного оператором GRANT.
TCL
Есть такое понятие, как транзакции. Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Для управления транзакциями существует TCL (Transaction Control Language — язык управления транзакциями). Операторы здесь следующие:
- BEGIN TRANSACTION — необходим для обозначения начала транзакции;
- COMMIT TRANSACTION — применяет изменения команд внутри транзакции;
- ROLLBACK TRANSACTION — откатывает транзакцию;
- SAVE TRANSACTION — указывает промежуточную точку сохранения внутри транзакции.
TCL есть только в тех БД, которые поддерживают транзакции. Самое время поговорить о видах БД.
Виды СУБД
Познакомимся с новым понятием — СУБД, системой управления базой данных.
Сергей Кузнецов в книге «Основы баз данных» описал СУБД как комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Получается что, СУБД — это SQL плюс комплекс программного обеспечения. Очень часто базы данных путают с системой управления базой данных. Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Есть много популярных СУБД, рассмотрим несколько из них.
Сервер базы данных
Современная СУБД должна удовлетворять ряду требований, важнейшее из которых — высокопроизводительный интеллектуальный сервер базы данных. Далее мы рассмотрим основные тенденции его развития и обсудим конкретные механизмы, в которых они находят свое воплощение.
Процесс технического совершенствования сервера базы данных пока остается невидимым для большинства пользователей современных СУБД. Поэтому при выборе той или иной системы они, как правило, не учитывают ни технический уровень решений, заложенных в механизм его функционирования, ни влияние этих решений на общую производительность СУБД. Между тем ее качество определяется отнюдь не богатством интерфейсов с пользователем, не разнообразием средств поддержки разработок, а в первую очередь зависит от особенностей архитектуры сервера базы данных. Далее будут рассмотрены модели технологии «клиент-сервер», определено место сервера БД в этих моделях и кратко описаны важнейшие механизмы сервера БД — процедуры, правила (триггеры), события. Последние будут проиллюстрированы примерами, в которых использован диалект SQL, принятый в СУБД Ingres.
2.1. Технология и модели «клиент-сервер».
«Клиент-сервер» — это модель взаимодействия компьютеров в сети. Как правило, компьютеры не являются равноправными. Каждый из них имеет свое, отличное от других, назначение, играет свою роль. Некоторые компьютеры в сети владеют и распоряжается информационно-вычислительными ресурсами, такими как процессоры, файловая система, почтовая служба, служба печати, база данных. Другие же компьютеры имеют возможность обращаться к этим службам, пользуясь услугами первых. Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса, а компьютер, желающий им воспользоваться — клиентом. Конкретный сервер определяется видом ресурса, которым он владеет. Так, если ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого — обслуживать запросы клиентов, связанные с обработкой данных; если ресурс — это файловая система, то говорят о файловом сервере, или файл-сервере, и т. д.
В сети один и тот же компьютер может выполнять роль как клиента, так и сервера. Например, в информационной системе, включающей персональные компьютеры, большую ЭВМ и мини-компьютер под управлением UNIX, последний может выступать как в качестве сервера базы данных, обслуживая запросы от клиентов — персональных компьютеров, так и в качестве клиента, направляя запросы большой ЭВМ.
Этот же принцип распространяется и на взаимодействие программ. Если одна из них выполняет некоторые функции, предоставляя другим соответствующий набор услуг, то такая программа выступает в качестве сервера. Программы, которые пользуются этими услугами, принято называть клиентами. Так, ядро реляционной SQL-ориентированной СУБД часто называют сервером базы данных, или SQL-сервером, а программу, обращающуюся к нему за услугами по обработке данных — SQL-клиентом.
Первоначально СУБД имели централизованную архитектуру (рис.1). В ней сама СУБД и прикладные программы, которые работали с базами данных, функционировали на центральном компьютере (большая ЭВМ или мини-компьютер). Там же располагались базы данных. К центральному компьютеру были подключены терминалы, выступавшие в качестве рабочих мест пользователей. Все процессы, связанные с обработкой данных, как то: поддержка ввода, осуществляемого пользователем, формирование, оптимизация и выполнение запросов, обмен с устройствами внешней памяти и т.д., выполнялись на центральном компьютере, что предъявляло жесткие требования к его производительности. Особенности СУБД первого поколения напрямую связаны с архитектурой систем больших ЭВМ и мини-компьютеров и и адекватно отражают все их преимущества и недостатки. Однако нас больше интересует современное состояние многопользовательских СУБД, для которых архитектура «клиент-сервер» стала фактическим стандартом.
Для более четкого представления об ее особенностях необходимо рассмотреть несколько моделей технологии «клиент-сервер», что и будет сделано.
Если предполагается, что проектируемая информационная система (ИС) будет иметь технологию «клиент-сервер», то это означает, что прикладные программы, реализованные в ее рамках, будут иметь распределенный характер. Иными словами, часть функций прикладной программы (или, проще, приложения) будет реализована в программе-клиенте, другая — в программе-сервере, причем для их взаимодействия будет определен некоторый протокол.
Основной принцип технологии «клиент-сервер» заключается в разделении функций стандартного интерактивного приложения на четыре группы, имеющие различную природу. Первая группа — это функции ввода и отображения данных. Вторая группа объединяет чисто прикладные функции, характерные для данной предметной области (например, для банковской системы — открытие счета, перевод денег с одного счета на другой и т.д.). К третьей группе относятся фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т.д.). Наконец, функции четвертой группы — это служебные функции (играющие роль связок между функциями первых трех групп.
В соответствии с этим в любом приложении выделяются следующие логические компоненты:
· компонент представления, реализующий функции первой группы;
· прикладной компонент, поддерживающий функции второй группы;
· компонент доступа к информационным ресурсам, поддерживающий функции третьей групп, а также вводятся и уточняются соглашения о способах их взаимодействия (протокол взаимодействия).
Различия в реализациях технологии «клиент-сервер» определяются четырьмя факторами. Во-первых, тем, в какие виды программного обеспечения интегрированы каждый из этих компонентов. Во-вторых, тем, какие механизмы программного обеспечения используются для реализации функций всех трех групп. Во-третьих, как логические компоненты распределяются между компьютерами в сети. В-четвертых, какие механизмы используются для связи компонентов между собой.
Выделяются четыре подхода, реализованные в моделях:
· модель файлового сервера (File Server — FS);
· модель доступа к удаленным данным (Remote Data Access — RDA);
· модель севера базы данных (DataBase Server — DBS);
· модель сервера приложений (Application Server — AS).
FS-модель является базовой для локальных сетей персональных компьютеров. Не так давно она была исключительно популярной среди отечественных разработчиков, использовавших такие системы, как FoxPRO, Clipper, Clarion, Paradox и т.д. Суть модели проста и всем известна. Один из компьютеров в сети считается файловым сервером и предоставляет услуги по обработке файлов другим компьютерам. Файловый сервер работает под управлением сетевой операционной системы (например, Novell NetWare) и играет роль компонента доступа к информационным ресурсам (то есть к файлам). На других компьютерах в сети функционирует приложение, в кодах которого совмещены компонент представления и прикладной компонент (рис.2). Протокол обмена представляет собой набор низкоуровневых вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере.
FS-модель послужила фундаментом для расширения возможностей персональных СУБД в направлении поддержки многопользовательского режима. В таких системах на нескольких персональных компьютерах выполняется как прикладная программа, так и копия СУБД, а базы данных содержатся в разделяемых файлах, которые находятся на файловом сервере. Когда прикладная программа обращается к базе данных, СУБД направляет запрос на файловый сервер. В этом запросе указаны файлы, где находятся запрашиваемые данные. В ответ на запрос файловый сервер направляет по сети требуемый блок данных. СУБД, получив его, выполняет над данными действия, которые были декларированы в прикладной программе.
К технологическим недостаткам модели относят высокий сетевой трафик (передача множества файлов, необходимых приложению), узкий спектр операций манипуляции с данными («данные — это файлы»), отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы) и т.д. Собственно, перечисленное не есть недостатки, но — следствие внутренне присущих FS-модели ограничений, определяемых ее характером. Недоразумения возникают, когда FS-модель используют не по назначению, например, пытаются интерпретировать как модель сервера базы данных. Место FS-модели в иерархии моделей «клиент-сервер» — это место модели файлового сервера, и ничего более. Именно поэтому обречены на провал попытки создания на основе FS-модели крупных корпоративных систем — попытки, которые предпринимались в недавнем прошлом и нередко предпринимаются сейчас.
Более технологичная RDA-модель существенно отличается от FS-модели характером компонента доступа к информационным ресурсам. Это, как правило, SQL-сервер. В RDA-модели коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Последний поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается либо операторами специального языка (языка SQL, например, если речь идет о базах данных), либо вызовами функций специальной библиотеки (если имеется соответствующий интерфейс прикладного программирования — API).
Клиент направляет запросы к информационным ресурсам (например, к базам данных) по сети удаленному компьютеру. На нем функционирует ядро СУБД, которое обрабатывает запросы, выполняя предписанные в них действия, и возвращает клиенту результат, оформленный как блок данных (рис.3). При этом инициатором манипуляций с данными выступают программы, выполняющиеся на компьютерах-клиентах, в то время как ядру СУБД отводится пассивная роль — обслуживание запросов и обработка данных. В Разделе 2 будет показано, что такое распределение обязанностей между клиентами и сервером базы данных не догма — сервер БД может играть более активную роль, чем та, которая предписана ему традиционной парадигмой.
RDA-модель избавляет от недостатков, присущих как системам с централизованной архитектурой, так и системам с файловым сервером.
Прежде всего перенос компонента представления и прикладного компонента на компьютеры-клиенты существенно разгружает сервер БД, сводя к минимуму общее число процессов операционной системы. Сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций. Это становится возможным благодаря отказу от терминалов и оснащению рабочих мест компьютерами, которые обладают собственными локальными вычислительными ресурсами, полностью используемыми программами переднего плана. С другой стороны, резко уменьшается загрузка сети, так как по ней передаются от клиента к серверу не запросы на ввод-вывод (как в системах с файловым сервером), а запросы на языке SQL, их объем существенно меньше.
Основное достоинство RDA-модели — унификация интерфейса «клиент-сервер» в виде языка SQL. Действительно, взаимодействие прикладного компонента с ядром СУБД невозможно без стандартизованного средства общения. Запросы, направляемые программой ядру, должны быть понятны обоим. Для этого их следует сформулировать на специальном языке. Но в СУБД уже существует язык SQL, о котором уже шла речь . Поэтому целесообразно использовать его не только в качестве средства доступа к данным, но и стандарта общения клиента и сервера.
Такое общение можно сравнить с беседой нескольких человек, когда один отвечает на вопросы остальных (вопросы задаются одновременно). Причем делает это он так быстро, что время ожидания ответа приближается к нулю. Высокая скорость общения достигается прежде всего благодаря четкой формулировке вопроса, когда спрашивающему и отвечающему не нужно дополнительных консультаций по сути вопроса. Беседующие обмениваются несколькими короткими однозначными фразами, им ничего не нужно уточнять.
К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие клиента и сервера посредством SQL-запросов существенно загружает сеть. Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно из-за совмещения в одной программе различных по своей природе функций (функции представления и прикладные). Более подробно о недостатках RDA-модели сказано в п. 2.3.1.
Наряду с RDA-моделью все большую популярность приобретает перспективная DBS-модель (рис. 4). Последняя реализована в некоторых реляционных СУБД (Informix, Ingres, Sybase, Oracle). Ее основу составляет механизм хранимых процедур — средство программирования SQL-сервера. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД. Более подробно о хранимых процедурах рассказано в п. 2.3.3.
В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Там же выполняется компонент доступа к данным, то есть ядро СУБД. Достоинства DBS-модели очевидны: это и возможность централизованного администрирования прикладных функций, и снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур), и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. К недостаткам модели можно отнести ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по изобразительным средствам и функциональным возможностям с языками третьего поколения, такими как C или Pascal. Сфера их использования ограничена конкретной СУБД, в большинстве СУБД отсутствуют возможности отладки и тестирования разработанных хранимых процедур.
На практике часто используется смешанные модели, когда поддержка целостности базы данных и некоторые простейшие прикладные функции поддерживаются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте (RDA-модель). Так или иначе современные многопользовательские СУБД опираются на RDA- и DBS-модели и при создании ИС, предполагающем использование только СУБД, выбирают одну из этих двух моделей либо их разумное сочетание.
В AS-модели (рис.5) процесс, выполняющийся на компьютере-клиенте, отвечает, как обычно, за интерфейс с пользователем (то есть осуществляет функции первой группы). Обращаясь за выполнением услуг к прикладному компоненту, этот процесс играет роль клиента приложения (Application Client — AC). Прикладной компонент реализован как группа процессов, выполняющих прикладные функции, и называется сервером приложения (Application Server — AS). Все операции над информационными ресурсами выполняются соответствующим компонентом, по отношению к которому AS играет роль клиента. Из прикладных компонентов доступны ресурсы различных типов — базы данных, очереди, почтовые службы и др.
RDA- и DBS-модели опираются на двухзвенную схему разделения функций. В RDA-модели прикладные функции приданы программе-клиенту, в DBS-модели ответственность за их выполнение берет на себя ядро СУБД. В первом случае прикладной компонент сливается с компонентом представления, во-втором — интегрируется в компонент доступа к информационным ресурсам. В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения, для его определения используются универсальные механизмы многозадачной операционной системы, и стандартизованы интерфейсы с двумя другими компонентами. AS-модель является фундаментом для мониторов обработки транзакций (Transaction Processing Monitors — TPM), или, проще, мониторов транзакций, которые выделяются как особый вид программного обеспечения. Мониторы транзакций — предмет Раздела 4.
В заключение отметим, что, часто, говоря о сервере базы данных, подразумевают как компьютер, так и программное обеспечение — ядро СУБД. При описании архитектуры «Клиент-сервер» под сервером базы данных мы имели в виду компьютер. Далее сервер базы данных будет пониматься как программное обеспечение — ядро СУБД.
2.2. Эволюция серверов баз данных
В период создания первых СУБД технология «клиент-сервер» только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия такого типа, в современных же системах он жизненно необходим.
Чтобы понять суть проблемы, рассмотрим эволюцию серверов баз данных. Первое время доминировала модель, когда управление данными (функция Сервера) и взаимодействие с пользователем были совмещены в одной программе (рис.6a). Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала парадигме «один-к-одному» (рис.6б), то есть сервер обслуживал запросы ровно одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов. Выделение сервера в отдельную программу — революционный шаг, позволяющий, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети (рис.7). Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы.
Проблемы, возникающие в модели «один-к-одному», решаются в архитектуре систем с выделенным сервером, способным обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (рис.8). Логически каждый клиент связан с сервером отдельной нитью (thread) или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой (multi-threaded).
Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей (trashing). С другой стороны, возможность взаимодействия с одним сервером многих клиентов позволяет в полной степени использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что значительно уменьшает потребности в памяти и общее число процессов операционной системы. Например, системой с архитектурой «один-к-одному» будет создано 50 копий процессов СУБД для 50 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один сервер.
Однако такое решение привносит новую проблему. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три.
В некоторых системах эта проблема решается заменой выделенного сервера на диспетчер или виртуальный сервер (virtual server) (рис.9), который теряет право монопольно распоряжаться данными, выполняя только функции диспетчеризации запросов к актуальным серверам. Таким образом, в архитектуру системы добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки (load balancing) и ограничивает возможности управления взаимодействием «клиент-сервер». Во-первых, становиться невозможным направить запрос от конкретного клиента конкретному серверу, во-вторых, серверы становятся равноправными — нет возможности устанавливать приоритеты для обслуживания запросов.
Подобная организация взаимодействия «клиент-сервер» является аналогом банка, где имеется несколько окон кассиров, и банковский служащий (диспетчер), направляет каждого вновь пришедшего посетителя (клиента) к свободному кассиру (актуальному серверу). Система работает нормально, пока все посетители равноправны (имеют равные приоритеты), однако, стоит лишь появиться посетителям с высшим приоритетом (которые должны обслуживаться в специальном окне), как возникают проблемы. Учет приоритета клиентов особенно важен в системах оперативной обработки транзакций, однако именно эту возможность не может предоставить архитектура систем с диспетчеризацией.
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если эти два условия выполнены, то есть основание говорить о многопотоковой архитектуре с несколькими серверами (multi-threaded, multi-server architecture)
2.3. Активный сервер
Действительно профессиональные СУБД обладают мощным активным сервером базы данных. Это не просто технические новшество. Идея активного сервера коренным образом изменяет представление о роли, масштабах и принципах использования СУБД, а в чисто практическом плане позволяет выбрать современные, эффективные методы построения глобальных информационных систем.
Идея активного интеллектуального сервера БД возникла не сама по себе — она стала ответом на задачи реальной жизни. В Разделе 1 было сформулировано общее представление о базе данных. Однако вдумчивый читатель может его расширить. Действительно, объекты реального мира, помимо непосредственных, прямых связей, имеют друг с другом более сложные причинно-следственные связи; они динамичны, находятся в постоянном изменении. Эти связи и процессы должны каким-то образом отражаться и в базе данных, если мы имеем в виду не статичное хранилище данных, а информационную модель маленькой части реального мира. Иными словами, в базе данных, помимо собственно данных и непосредственных связей между ними, должны хранится знания о данных, а сама база должна адекватно отражать процессы, происходящие в реальном мире. Значит, необходимо иметь средства хранения и управления такой информацией.
2.3.1. Актуальные задачи
Указанные требования выливаются в решение следующих задач.
Во-первых, необходимо, чтобы база данных в любой момент правильно отражала состояние предметной области — данные должны быть взаимно непротиворечивыми. Пусть, например, база данных Кадры хранит сведения о рядовых сотрудниках, отделах, в которых они работают, и их руководителях. Нужно учесть следующие правила: каждый сотрудник должен быть подчинен реальному руководителю; если руководитель уволился, то все его сотрудники переходят в подчинение другому, а отдел реорганизуется; во главе каждого отдела должен стоять реальный руководитель; если отдел сокращен, то его руководитель переводится в резерв на выдвижение и т.д.
Во-вторых, база данных должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rule). Завод может нормально работать, только в том случае, если на складе имеется достаточный запас деталей определенной номенклатуры. Следовательно, как только количество деталей некоторого типа станет меньше минимально допустимого, завод должен докупить эти детали в нужном количестве.
В-третьих, необходим постоянный контроль за состоянием базы данных, отслеживание всех изменений, и адекватная реакция на них. Например, в автоматизированной системе управления производством датчики контролируют температуру инструмента; она периодически передается в базу данных и там сохраняется; как только температура инструмента превышает максимально возможное значение, он отключается.
В-четвертых, необходимо, чтобы возникновение некоторой ситуации в базе данных четко и оперативно влияло на ход выполнения прикладной программы. Многие программы требуют оперативного оповещения о всех происходящих в базе данных изменениях. Так, в системах автоматизированного управления производством необходимо моментально уведомлять программы о любых изменениях параметров технологических процессов, когда последние хранятся в базе данных. Почтовая служба требует оперативного уведомления получателя, как только получено новое сообщение. Брокер на бирже СУБД должен немедленно получать сообщение об изменении цены акций, поскольку промедление в несколько секунд грозит большими потерями.
Оповещение о возникновении определенного состояния базы данных и изменениях в ней может потребоваться в любом учреждении для контроля прохождения документов. Если документ, который должен быть просмотрен и последовательно завизирован несколькими руководителями, хранится в базе данных, то каждый из них в свою очередь будет оперативно уведомлен о поступлении документа ему на подпись.
Важная проблема СУБД — контроль типов данных. В Разделе 1 уже говорилось о том, что в базе данных каждый столбец в любой таблице содержит данные некоторых типов. Тип данных определяется при создании таблицы. Каждому столбцу присваивается один из стандартных типов данных, разрешенных в СУБД. Стало быть, в базе данных можно хранить только данные стандартных типов — числа, целые и вещественные, строки символов, данные типа «дата», «время» и «денежная единица» — репертуар реальной СУБД ограничен именно этими типами данных. Как же быть с нестандартными данными? Ведь в реальной жизни требуется хранить и обрабатывать данные в значительно более широком диапазоне — плоскостные и пространственные координаты, единицы различных метрик, пятидневные недели (рабочая неделя, в которой сразу после пятницы следует понедельник), дроби, не говоря уже о графических изображениях.
2.3.2. Традиционные подходы
До недавнего времени функции управления знаниями оставались за границами возможностей реляционных СУБД или были очень ограниченны.
Знания о предметной области традиционно включались непосредственно в прикладные программы, для чего использовались возможности процедурных языков программирования. Этот подход в подавляющем большинстве случаев преобладает и сейчас.
Рассмотрим, например, базу данных Склад, хранящую информацию о наличии деталей на заводском складе. Прикладная программа Складской Учет обеспечивает учет имеющихся и вновь поступающих деталей. В ее функции входит просмотр содержимого базы данных, добавление информации о новых деталях, замена снятых с производства деталей на новые и т.д. В программе реализованы некоторые правила, например «В любой момент времени количество деталей типа «втулка» не должно быть меньше 1000″ (ситуация со втулками на производстве всегда напряженная). Нетрудно понять, что оно должно применяться только в том случае, когда количество втулок уменьшается. Значит, нужно проверить: а не уменьшилось ли оно настолько, что стало меньше 1000. Если это произошло, то нужно срочно направить на завод-изготовитель письмо с просьбой отгрузить нужное количество втулок, если, конечно, такое письмо не было направлено до этого.
А чтобы это правило применялось, программа должна периодически, через определенные интервалы времени опрашивать значение в столбце Количество таблицы Деталь для всех строк, которые удовлетворяют условию Деталь. Название =»Втулка». Если это значение становится меньше 1000, программа должна послать письмо на завод-изготовитель.
Фрагмент программы указан в Примере 1.
… SELECT Количество, Номер_поставщика FROM Деталь WHERE Название = «Втулка»; IF (Количество < 1000) THEN BEGIN SELECT Адрес_поставщика FROM Поставщик WHERE Номер = Номер_поставщика; Послать письмо(Адрес_поставщика, 1000-Количество); END ELSE Ничего не делать … { … ВЫБРАТЬ Количество, Номер_поставщика ИЗ Деталь ГДЕ Название = «Втулка»; ЕСЛИ (Количество < 1000) ТО НАЧАТЬ ВЫБРАТЬ Адрес_поставщика ИЗ Поставщик ГДЕ Номер = Номер_поставщика; Послать письмо(Адрес_поставщика, 1000-Количество); ЗАКОНЧИТЬ ИНАЧЕ Ничего не делать … }
Пример 1.
В чем недостатки такого подхода?
Во-первых, реализация правил перегружает прикладную программу и усложняет ее написание и понимание. Во-вторых, и это более существенный недостаток, когда изменяется само правило, изменения должны быть отражены в тексте программы. Когда же правила изменяются кардинальным образом, разработчику приходится пересматривать логику выполнения программы и практически переписывать ее заново.
Удобнее оставить за прикладными программами только базовые алгоритмы управления данными, а часто меняющиеся правила, которые действуют во внешнем мире, вынести за рамки программ и оформить как-то иначе. В противном случае разработчиков ждут неприятные сюрпризы.
Рассмотрим для примера прикладную банковскую систему. При ее создании разработчики в алгоритмах управления данными учли те правила финансовой деятельности, которые диктовались действующим законодательством. Предположим теперь, что законы претерпели некоторые изменения (что в наше время происходит слишком часто!). Естественно, эти изменения должны быть немедленно отражены и в алгоритмах управления данными, что повлечет за собой необходимость модификации всех прикладных программ, составляющих информационную систему.
Это огромная работа — нужно исправить и отладить программы, откомпилировать и собрать их, внести изменения в документацию и переобучить персонал.
С другой стороны, правила, о которых идет речь, не должны противоречить друг другу. Когда их реализует группа разработчиков, нет никаких гарантий взаимной непротиворечивости правил. Фактически правила должен формулировать и контролировать один человек — администратор базы данных. При традиционном подходе практически невозможно обеспечить централизованный контроль за взаимным соответствием правил, если они разбросаны по многим программам, и, что более важно для коммерческих организаций, практически невозможно проконтролировать преднамеренное искажение правил программистами.
Таким образом, включение правил в прикладные программы, когда серверу отводится пассивная роль поставщика и хранителя данных, а вся интеллектуальная часть реализуется в программе, представляет собой устаревшую технологию. Она чревата большими накладными расходами при изменении правил и не обеспечивает централизованного контроля за их непротиворечивостью. Ясно, что эта технология имеет в своей основе столь популярную ныне RDA-модель (о ней речь шла выше).
Традиционное решение задач контроля за состоянием базы данных и уведомления прикладных программ о всех происходящих в ней событиях опирается на механизмы опроса (polling) прикладными программами базы данных, которому присущи следующие недостатки.
Прикладная программа не может непрерывно опрашивать базу данных, так как это приведет к перегрузке сервера бесполезными запросами. Опрос производится через интервалы времени, которые определяет программист. Следовательно, если в базе данных происходят какие-либо изменения, то они выявляются не сразу, а через какое-то время. Именно поэтому традиционное решение не обеспечивает оперативного оповещения, в прикладных же программах, работающих в реальном времени (см. примеры выше), это требование является ключевым. Постоянный опрос базы данных сильно сказывается на производительности системы — программы, опрашивающие базу данных, перегружают своими запросами сервер и сеть. Громоздкие конструкции в тексте программ, реализующие опрос, серьезно затрудняют ее написание и понимание.
Другое важное требование реальной жизни — синхронизация работы нескольких программ, обращающихся к базе данных. Рассмотрим пример. Финансовая система завода должна отслеживать поступление платежей за продукцию на некоторый счет. Как только деньги поступили (все знают, насколько это важное событие — «пришли деньги!»), все прикладные программы, включенные в финансовую систему, должны быть оповещены об этом. После этого каждая из них может предпринять некоторые действия. Так, программа Отгрузка Продукции должна найти в базе данных соответствующий заказ, определить номенклатуру заказанной продукции, ее количество, сроки поставки, сформировать и послать на склад готовой продукции заказ на отгрузку, распечатать сопроводительные документы — иными словами подготовить продукцию к отправке. Программа Бухгалтерия, в частности, должна по дате поступления денег определить, просрочен ли платеж, и, если это так, начислить штраф. Все эти действия активизируются событием в базе данных — поступлением денег на счет (в терминах реляционной СУБД это означает добавление новой строки в таблицу Платежи). Работа всех программ синхронизируется этим событием.
Традиционное решение проблемы синхронизации программ обеспечивается стандартными средствами многозадачной операционной системы. Однако такая синхронизация может быть связана с изменениями, происходящими в базе данных, только посредством постоянного опроса таблицы Платежи. Недостатки такого подхода очевидны — в нем взаимосвязь программ обеспечивается на уровне операционной системы, тогда как эту функцию, безусловно, должна выполнять СУБД. Кроме того, приходится привлекать программы опроса, недостатки которого мы уже обсуждали.
Общепринятый способ преодоления ограничения на типы данных в СУБД — приведение данных новых типов к стандартным. Как правило, данные новых типов рассматриваются как целые или вещественные числа, или как строки символов.
Рассмотрим пример. В ряде стран, в том числе и в США, для измерения длины наряду с привычными мерами метрической системоы используются также футы и дюймы. Правила выполнения арифметических операций в этой системе отличны от десятичной. Так, три фута одиннадцать дюймов плюс один дюйм равно четырем футам ( 3″11″ + 1″ = 4″). Стандартный набор типов данных не позволяет определить данные в этой системе и оперировать с ними. Они должны быть преобразованы в вещественные числа с плавающей точкой, то есть представлены соответственно, как 3.91666 (три фута одиннадцать дюймов) и 0.08333 (один дюйм). Выполнив операцию сложения (3.91666+0.08333=3.99999), мы убедимся, что такое представление приводит к потере точности (ведь результат должен быть равен четырем!).
Следовательно, прямое приведение новых типов данных к стандартным чревато ошибками — необходимо их преобразование в данные стандартных типов. Функции преобразования данных должны взять на себя прикладные программы (больше некому). В результате получается довольно громоздкая схема. Программа извлекает из базы данных данные новых типов, представленные как стандартные, преобразует и обрабатывает их, затем вновь преобразует и передает серверу для хранения. Сервер в обработке данных новых типов при такой схеме участия не принимает — ведь он рассматривает их как стандартные и будет обрабатывать как стандартные (и тогда возникнут ошибки!).
Сегодня, например, для отечественных банков актуальна проблема больших чисел. Масштаб расчетов настолько возрос, что в некоторых итоговых операциях фигурируют суммы, которые превосходят разрядную сетку для целых чисел. Поэтому в программах приходится преобразовывать целые числа в строки и наоборот, что не упрощает их логику. Хранение и обработка больших целых как вещественных приводит к потере точности, что в финансовой системе недопустимо.
Далее мы увидим, что решение проблемы заключается в определении нового типа данных «большие целые». Как только это сделано, сервер базы данных начинает «понимать» новый тип данных и выполнять над ним все операции, характерные для целых чисел.
Другое важнейшее требование к современным СУБД — возможность хранения неструктурированных объектов большого объема (Binary Large OBjects — BLOB). Отвечая на это требование, разработчики СУБД предусматривают такую возможность. Однако сервер лишь хранит такие объекты, не обладая возможностями их обработки. Например, работая с графическим объектами, сервер не делает различий между изображением автомобиля BMW и структурой ДНК. Сервер вынужден передавать их для интерпретации прикладной программе, которая сможет разобраться, кто есть кто.
Не следует забывать и о проблеме целостности. Если одна программа интерпретирует данные некоторого типа, преобразуя его в собственный формат, то ничто не мешает делать то же самое другой программе с той только разницей, что формат представления тех же данных будет уже другим. Это делает принципиально невозможным контроль целостности данных хотя бы потому, что различные программы интерпретируют их по-разному.
Отметим, что отсутствие в СУБД нестандартных типов данных заметно сказывается на их производительности, так как нормальное взаимодействие клиента и сервера возможно только тогда, когда и тот и другой адекватно воспринимают типы данных, с которыми ведется работа. Если используются типы данных, не известные серверу, то он вынужден передавать клиенту для обработки практически всю базу данных, что перегружает сеть и приводит к потере производительности. Фактически в такой схеме появление нестандартных типов данных приводит к деградации архитектуры системы к архитектуре с файловым сервером. Не понимая нового типа данных, сервер способен лишь послушно сохранять его, не умея сравнивать, сортировать, выполнять какие бы то ни было операции над данными.
С другой стороны, это ограничение приводит к тому, что основная тяжесть обработки данных нестандартных типов ложится на прикладные программы. При этом вопрос о целостности данных остается открытым, поскольку не поддерживается централизованный контроль типов данных, несомненно являющейся функцией сервера базы данных.
Итак, в традиционной технологии решение задач, о которых шла речь выше, ложится целиком на прикладные программы. Недостатки традиционной технологии — следствие того, что традиционно в СУБД в модели взаимодействия «клиент-сервер» последнему отводится в основном пассивная роль. Во-первых, сервер базы данных лишен функций хранения и обработки знаний о предметной области. Во-вторых, за границами возможностей сервера остается контроль за состоянием базы данных и программирование реакции на ее изменения. В-третьих, пассивный сервер не имеет средств отслеживания событий в базе данных, а также средств воздействия на работу прикладных программ и возможностей их синхронизации.
2.3.3. Современные решения
Идеи, реализованные в СУБД третьего поколения (пока, к сожалению, не во всех), заключаются в том, что знания выносятся за рамки прикладных программ и оформляются как объекты базы данных. Функции применения знаний начинает выполнять непосредственно сервер базы данных.
Такая архитектура суть воплощение концепции активного сервера. Она опирается на четыре «столпа»:
- процедуры базы данных
- правила (триггеры)
- события в базе данных
- типы данных, определяемые пользователем
Оперативная память сервера баз данных
Большой объем оперативной памяти, в идеале такой, чтобы закэшировать всю базу данных целиком. Работа с оперативной памятью на порядки быстрее, чем работа с жесткими дисками, поэтому чем бОльшим объемом памяти будет распологать сервер, тем лучше, при условии, что операционная система и само приложение сервера СУБД способны адресовать и работать с таким количеством памяти. Современные операционные системы и приложения фактически не имеют данных ограничений, т.к. способны адресовать до 64Гб и более. Двухпроцессорные серверы способны оснащаться 128Гб оперативной памяти, а четырех- и восьмипроцессорные — до 256Гб.
Дисковая подсистема сервера баз данных
Для получения максимальной производительности дисковой подсистемы на транзакционных задачах ее строят следующим образом: несколько жестких дисков объединяются в RAID-массив, т. к. в RAID-массиве операции чтения-записи происходят одновременно на нескольких дисках, то рост производительности (количества операций ввода-вывода в секунду, IOPS) растет пропорционально количеству жестких дисков в массиве. В качестве жестких дисков рекомендуется использовать диски SAS (Serial Attached SCSI)на 10000 об/мин или 15000 об/мин. Данные диски оптимизированы для работы на транзакционных нагрузках и по этому показателю имеют вдвое-втрое более высокую производительность, чем диски SATA. Кроме того, диски SAS изначально проектировались под работу в RAID-массивах и показывают практически линейный рост производительности массива при увеличении количества дисков в нем.
Вычислительная мощность сервера баз данных
Современные процессоры стали значительно производительнее, чем 2-3 года назад благодаря внедрению технологии многоядерности. Сейчас сервер с 8-ю ядрами (фактически процессорами) доступен практически каждой организации. Благодаря этому, появилась возможность обрабатывать существенные объемы информации на относительно недорогом оборудовании. Для «тяжелых» систем постепенно отпадает необходимость в приобретении дорогостоящих многопроцессорных RISC-систем, стоящих при равной производительности на порядки дороже. В настоящий момент существуют четырех- и восьмипроцессорные серверы стандартной архитектуры x86 с поддержкой четырех и даже шестиядерных процессоров, что позволяет иметь в одной системе до 32-х ядер.
Компания STSS рада предложить своим закачикам широкий спектр серверов для СУБД самого различного уровня. Начиная от небольших баз данных на 10-20 пользователей, и заканчивая системами корпоративного уровня с числом пользователей, превышающем 1000 человек.
Нами разработано уникальное решение — четырехпроцессорный сервер с большим количеством отсеков для жестких дисков. Уникальное сочетание высокой вычислительной мощности и высокопроизводительной дисковой подсистемы в одном конструктиве позволяет сэкономить до 50% по сравнению с традиционным решением — сервер + внешний RAID-массив
На нашем сайте серверы баз данных представлены в следующих разделах:
- Серверы 2 CPU
- Cерверы 4-8 CPU
Microsoft SQL Server
Продукт
| Разработчики: | Microsoft |
| Дата последнего релиза: | 2010/04/21 |
| Отрасли: | Информационные технологии |
| Технологии: | СУБД |
История
Исходный код MS SQL Server (до версии 7.0) основывался на коде Sybase SQL Server, и это позволило Microsoft выйти на рынок баз данных для предприятий, где конкурировали Oracle, IBM, и, позже, сама Sybase. Microsoft, Sybase и Ashton-Tate первоначально объединились для создания и выпуска на рынок первой версии программы, получившей название SQL Server 1.0 для OS/2 (около 1989 года), которая фактически была эквивалентом Sybase SQL Server 3.0 для Unix, VMS и др. Microsoft SQL Server 4.2 был выпущен в 1992 году и входил в состав операционной системы Microsoft OS/2 версии 1.3. Официальный релиз Microsoft SQL Server версии 4.21 для ОС Windows NT состоялся одновременно с релизом самой Windows NT (версии 3.1). Microsoft SQL Server 6.0 был первой версией SQL Server, созданной исключительно для архитектуры NT и без участия в процессе разработки Sybase.
К тому времени, как вышла на рынок ОС Windows NT, Sybase и Microsoft разошлись и следовали собственным моделям программного продукта и маркетинговым схемам. Microsoft добивалась исключительных прав на все версии SQL Server для Windows. Позже Sybase изменила название своего продукта на Adaptive Server Enterprise во избежание путаницы с Microsoft SQL Server. До 1994 года Microsoft получила от Sybase три уведомления об авторских правах как намёк на происхождение Microsoft SQL Server.
После разделения компании сделали несколько самостоятельных релизов программ. SQL Server 7.0 был первым сервером баз данных с настоящим пользовательским графическим интерфейсом администрирования. Для устранения претензий со стороны Sybase в нарушении авторских прав, весь наследуемый код в седьмой версии был переписан.
Версия SQL Server 2005 — была представлена в ноябре 2005 года. Запуск версии происходил параллельно запуску Visual Studio 2005. Существует также «урезанная» версия Microsoft SQL Server — Microsoft SQL Server Express; она доступна для скачивания и может бесплатно распространяться вместе с использующим её программным обеспечением.
С момента выпуска предыдущей версии SQL Server (SQL Server 2000) было осуществлено развитие интегрированной среды разработки и ряда дополнительных подсистем, входящих в состав SQL Server 2005. Изменения коснулись реализации технологии ETL (извлечение, преобразование и загрузка данных), входящей в состав компонента SQL Server Integration Services (SSIS), сервера оповещения, средств аналитической обработки многомерных моделей данных (OLAP) и сбора релевантной информации (обе службы входят в состав Microsoft Analysis Services), а также нескольких служб сообщений, а именно Service Broker и Notification Services. Помимо этого, были произведены улучшения в производительности.
Функциональность
Microsoft SQL Server в качестве языка запросов использует версию SQL, получившую название Transact-SQL (сокращённо T-SQL), являющуюся реализацией SQL-92 (стандарт ISO для SQL) с множественными расширениями. T-SQL позволяет использовать дополнительный синтаксис для хранимых процедур и обеспечивает поддержку транзакций (взаимодействие базы данных с управляющим приложением). Microsoft SQL Server и Sybase ASE для взаимодействия с сетью используют протокол уровня приложения под названием Tabular Data Stream (TDS, протокол передачи табличных данных). Протокол TDS также был реализован в проекте FreeTDS с целью обеспечить различным приложениям возможность взаимодействия с базами данных Microsoft SQL Server и Sybase.
Microsoft SQL Server также поддерживает Open Database Connectivity (ODBC) — интерфейс взаимодействия приложений с СУБД. Версия SQL Server 2005 обеспечивает возможность подключения пользователей через веб-сервисы, использующие протокол SOAP. Это позволяет клиентским программам, не предназначенным для Windows, кроссплатформенно соединяться с SQL Server. Microsoft также выпустила сертифицированный драйвер JDBC, позволяющий приложениям под управлением Java (таким как BEA и IBM WebSphere) соединяться с Microsoft SQL Server 2000 и 2005.
SQL Server поддерживает зеркалирование и кластеризацию баз данных. Кластер сервера SQL — это совокупность одинаково конфигурированных серверов; такая схема помогает распределить рабочую нагрузку между несколькими серверами. Все сервера имеют одно виртуальное имя, и данные распределяются по IP-адресам машин кластера в течение рабочего цикла. Также в случае отказа или сбоя на одном из серверов кластера доступен автоматический перенос нагрузки на другой сервер.
SQL Server поддерживает избыточное дублирование данных по трем сценариям:
- Снимок: Производится «снимок» базы данных, который сервер отправляет получателям.
- История изменений: Все изменения базы данных непрерывно передаются пользователям.
- Синхронизация с другими серверами: Базы данных нескольких серверов синхронизируются между собой. Изменения всех баз данных происходят независимо друг от друга на каждом сервере, а при синхронизации происходит сверка данных. Данный тип дублирования предусматривает возможность разрешения противоречий между БД.
В SQL Server 2005 встроена поддержка .NET Framework. Благодаря этому, хранимые процедуры БД могут быть написаны на любом языке платформы .NET, используя полный набор библиотек, доступных для .NET Framework, включая Common Type System (система обращения с типами данных в Microsoft .NET Framework). Однако, в отличие от других процессов, .NET Framework, будучи базисной системой для SQL Server 2005, выделяет дополнительную память и выстраивает средства управления SQL Server вместо того, чтобы использовать встроенные средства Windows. Это повышает производительность в сравнении с общими алгоритмами Windows, так как алгоритмы распределения ресурсов специально настроены для использования в структурах SQL Server.
Microsoft разработала конкурента Oracle Exadata и SAP HANA
Microsoft разработал новую технологию in-memory, которая будет в скором времени добавлена в SQL Server. Технология получила название Hekaton. Об этом 7 ноября 2012 года сообщил ComputerWorld.
Microsoft в стремлении ускорить процессы оперативной обработки транзакций (OLTP) добавил в SQL Server возможность использовать реляционные системы управления базами данных.
Планируется, что уже в следующей версии SQL Server будет включена возможность размещения части таблиц баз данных или даже все базы данных в памяти сервера. Так же будут добавлены дополнительные инструменты для упрощенного запуска технологии.
По словам генерального менеджера Microsoft Дуга Леланда, технология Hekaton сейчас тестируется некоторыми заказчиками. Но о более точных сроках ее запуска пока не сообщает.
Microsoft утверждает, что сервер будет быстрее выполнять операции,если необходимые таблицы и базы данных будут в памяти, а не записаны на диск, к которому необходимо будет обращаться. Гигант уверен, что технология позволит увеличить скорость обработки данных до 50 раз по сравнению с аналогичными системами для SQL Server.
Основными направлениями для использования Hekaton являются банковские онлайн системы, ERP, и другие транзакционные системы, которым необходимо оперативно связываться и использовать базы данных. Технология может быть установлена на одном сервере и далее масштабирована на остальные сервера, т.к. она не имеет жестких ограничений по используемой памяти.
Выход Hekaton может стать серьезной головной болью для таких компаний как Oracle с ее продуктом Oracle Exadata и для SAP, в частности SAP HANA. Это обусловлено тем, что технология значительно упрощает ИТ-архитектуру и снимает необходимость докупать компоненты для обработки данных, как это реализовано у конкурентов.
Дуг Леланд утверждает, что Hekaton — не первый опыт Microsoft в работе с технологиями in-memory. Так в офисном приложении Microsoft Excel используются технологии PowerPivot и Power View, позволяющие оперативно манипулировать большим объемом данных.
Microsoft также объявила о скором выходе следующей версии Data Warehouse Appliance, SQL Server 2012 Parallel Data Warehouse (PDW). А для SQL Server 2012 выпущен пакет обновлений, который в частности включает возможность пользователям Exel 2013 работать с данными, хранящимися на SQL Server.
Разработка приложений
Microsoft и другие компании производят большое число программных средств разработки, позволяющих разрабатывать бизнес-приложения с использованием баз данных Microsoft SQL Server. Microsoft SQL Server 2005 включает в себя также Common Language Runtime (CLR) Microsoft .NET, позволяющий реализовывать хранимые процедуры и различные функции приложениям, разработанным на языках платформы .NET (например, VB.NET или C#). Предыдущие версии средств разработки Microsoft использовали только API для получения функционального доступа к Microsoft SQL Server.
SQL Server Express Edition
Microsoft SQL Server Express является бесплатно распространяемой версией SQL Server, развитием системы MSDE. Данная версия имеет некоторые технические ограничения. Такие ограничения делают её непригодной для развертывания больших баз данных, но она вполне годится для ведения программных комплексов в масштабах небольшой компании. Содержит полноценную поддержку новых типов данных, в том числе XML-спецификации. Фактически, это полноценный MS SQL Server, включая все его компоненты программирования, поддержку национальных алфавитов и Unicode. Поэтому используется в приложениях, при проектировании или для самостоятельного изучения. Нет никаких препятствий для дальнейшего развёртывания накопленной базы данных на MS SQL Server неэкспрессной версии. В 2007 году Microsoft выпустила отдельную утилиту с графическим интерфейсом для администрирования данной версии, которая также доступна для бесплатного скачивания с сайта корпорации.
Особенности линейки B
Все серверы этой линейки — рэковые: они изначально предназначены для установки в стойку или шкаф. Размер всех моделей линейки B — 1U.
Во всех моделях используется оперативная память DIMM DDR4 и диски SATA III (6Gb/s) 2.5″ SSD.
Все серверы поддерживают замену дисков в горячем режиме и не содержат оптического привода. Функция горячей замены чрезвычайно важна: она позволяет заменить неисправный блок, не останавливая работу сервера.
От B1 до B3
Первые три модели данной линейки.
Какие у них параметры?
— платформа Supermicro 5019S-M SYS-5019S-M;
— поддержка одного процессора;
— 32 Гб оперативной памяти;
— блок питания мощностью 350 Вт;
— контроллер дисков Software RAID.
Чем можно дополнить? В оба сервера можно установить:
— один процессор с разъемом LGA 1151 серий Intel Xeon E3 1200v5/1200v6 и Intel Core i3-6000/7000, Pentium G4000, Celeron G3000;
— четыре модуля памяти и четыре диска 3,5”.
Серверы B1 и B2 работают на базе процессора Intel Pentium G4620, но отличаются объемом SSD:
ANDPRO-B1 — два диска по 240 Гб.
ANDPRO-B2 — два диска по 480 Гб.
ANDPRO-B3 отличается от двух предыдущих моделей процессором Intel Xeon E3 1230v6 и объемом SSD два диска по 480 Гб.
От B4 до B6
Еще три, более продвинутые модели данной линейки.
Какие у них параметры?
— платформа Supermicro 5019S-MN4 SYS-5019S-MN4;
— поддержка одного процессора (Intel Xeon E3 1275v6);
— 64 Гб оперативной памяти;
— блок питания мощностью 350 Вт;
— контроллер дисков Software RAID.
Чем можно дополнить? В оба сервера можно установить:
— один процессор с разъемом LGA 1151 серий Intel Xeon E3 1200v5/1200v6 и Intel Core i3-6000/7000, Pentium G4000, Celeron G3000;
— четыре модуля памяти и четыре диска формата 3.5”.
Серверы отличаются друг от друга объемом SSD:
ANDPRO-B4 — два диска по 480 Гб.
ANDPRO-B5 — два диска по 240 Гб и два диска по 200 Гб.
ANDPRO-B6 — два диска по 240 Гб и два диска по 480 Гб.
B7
ANDPRO-B7 — это следующая модель линейки B.
Какие у него параметры?
— платформа Intel Silver Pass R1304SPOSHORR;
— поддержка одного процессора (Intel Xeon E3 1270v6);
— 64 Гб оперативной памяти;
— четыре SSD-накопителя формата 3,5» по 480 Гб;
— два блока питания мощностью 450 Вт;
— контроллер дисков RMS3CC040.
Чем можно дополнить? В оба сервера можно установить:
— один процессор с разъемом LGA 1151 серии Intel Xeon E3 1200v5;
— четыре модуля памяти и четыре диска формата 3.5”.
От B8 до B12
Эти четыре модели, в отличие от предыдущих, являются серверами энтерпрайз-уровня.
Какие у них параметры?
— платформа Intel Silver Pass R1304SPOSHORR;
— поддержка двух процессоров (Intel Xeon E5 2620v4);
— 128 Гб оперативной памяти (кроме модели B10 с 256 Гб);
— один блок питания мощностью 1100 Вт;
— контроллер дисков Software RAID.
Чем можно дополнить? В оба сервера можно установить:
— два процессора с разъемом LGA 2011v3 серии Intel Xeon E5 2600v3;
— 24 модуля памяти и восемь диска формата 2.5”;
— один блок питания мощностью 750 Вт.
Между собой они отличаются объемом SSD-накопителей:
ANDPRO-B8 — два диска по 240 Гб и два диска по 400 Гб.
ANDPRO-B9 — два диска по 240 Гб и четыре диска по 480 Гб.
ANDPRO-B10 — два диска по 240 Гб и четыре диска по 480 Гб (а также 256 Гб оперативной памяти вместо 128 Гб).
ANDPRO-B12 — два диска по 480 Гб, а также два HDD-накопителя SAS 3.0 (12Gb/s) по 2 Тб и один SSD PCI-E 3.0×4 PCI-E.
B13
Как в и предыдущей модели, в ANDPRO-B13 установлены не только SATA III (6Gb/s) 2.5″ SSD.
Какие у него параметры?
— платформа Intel Wildcat Pass R1208WT2GSR;
— поддержка двух процессоров (Intel Xeon E5 2680v4);
— 128 Гб оперативной памяти;
— два SSD-накопителя формата 2,5” по 240 Гб, а также два HDD-накопителя SAS 3.0 (12Gb/s) формата 2,5” по 2 Тб и один SSD PCI-E 3.0×4 PCI-E объемом 2 Тб;
— один блок питания мощностью 1100 Вт;
— контроллер дисков RMS3CC080.
Чем можно дополнить? В оба сервера можно установить:
— два процессора с разъемом LGA 2011v3 серии Intel Xeon E5 2600v3;
— 24 модуля памяти и восемь диска формата 2.5”;
— один блок питания мощностью 750 Вт.
B14 и B15
Последние и самые мощные модели энтерпрайз-уровня в линейке B.
Какие у них параметры?
— платформа Intel Wolf Pass R1208WFTYSR;
— поддержка двух процессоров (предустановлен Intel Xeon Gold 6138: один в B14 и два в B15);
— два блока питания мощностью 1100 Вт;
— два SSD формата 2,5» по 240 Гб, а также один SSD PCIe NVMe 3.0 x4 PCI-E объемом 375 Гб и один SSD PCIe NVMe 3.0 x4 PCI-E объемом 2Тб;
— контроллер дисков RMS3CC080.
Чем можно дополнить? В оба сервера можно установить:
— два процессора с разъемом LGA 3647;
— 24 модуля памяти и восемь диска формата 2.5”.
Между собой они отличаются объемом оперативной памяти: 192 Гб в ANDPRO-B14 и 384 Гб в ANDPRO-B15.
- https://gb.ru/posts/chto-takoe-sql-i-kak-on-rabotaet
- https://www.zeluslugi.ru/info-czentr/it-glossary/term-sql
- https://www.osp.ru/dbms/1995/02/13031414
- http://www.STSS.ru/solutions/database_server.html
- https://www.tadviser.ru/index.php/%D0%9F%D1%80%D0%BE%D0%B4%D1%83%D0%BA%D1%82:Microsoft_SQL_Server
- https://zen.yandex.ru/media/andpro/kak-vybrat-server-baz-dannyh-5d6fbf9b32335400ad58c28b