Содержание
- 1 Создание таблицы с данными
- 2 Написание предложений GROUP BY
- 3 Агрегатные функции (COUNT, SUM, AVG)
- 4 Работа с несколькими группами
- 5 Синтаксис GROUP BY
- 6 Пример SQL GROUP BY
- 7 GROUP BY с JOIN
- 8 Группируем данные с помощью запроса group by
- 9 Использование конструкции GROUP BY с операцией ROLLUP
- 10 Использование конструкции GROUP BY с операцией CUBE
- 11 Использование конструкции GROUP BY с операцией GROUPING
- 12 Использование конструкции GROUP BY с операцией GROUPING SETS
- 13 Использование конструкции GROUP BY с операцией HAVING
- 14 Группировка с агрегатными функциями
- 15 Обновление агрегатных функций
- 16 Когда следует использовать GROUP BY в SQL?
- 17 SQL Group By по нескольким столбцам
Создание таблицы с данными
Для нашего примера мы создадим таблицу, в которой будут храниться записи о продажах различных продуктов в разных точках.
Таблицу мы назовем sales. Это будет простое представление продаж в магазинах: название локации, название продукта, цена и время продажи.
Если бы мы создавали такую таблицу для настоящего приложения, мы бы использовали внешние ключи к другим таблицам (например, locations или products). Но чтобы показать работу GROUP BY, мы создадим простые TEXT-столбцы.
Давайте создадим нашу таблицу и внесем в нее кое-какие данные о продажах:
CREATE TABLE sales( location TEXT, product TEXT, price DECIMAL, sold_at TIMESTAMP ); INSERT INTO sales(location, product, price, sold_at) VALUES (‘HQ’, ‘Coffee’, 2, NOW()), (‘HQ’, ‘Coffee’, 2, NOW() — INTERVAL ‘1 hour’), (‘Downtown’, ‘Bagel’, 3, NOW() — INTERVAL ‘2 hour’), (‘Downtown’, ‘Coffee’, 2, NOW() — INTERVAL ‘1 day’), (‘HQ’, ‘Bagel’, 2, NOW() — INTERVAL ‘2 day’), (‘1st Street’, ‘Bagel’, 3, NOW() — INTERVAL ‘2 day’ — INTERVAL ‘1 hour’), (‘1st Street’, ‘Coffee’, 2, NOW() — INTERVAL ‘3 day’), (‘HQ’, ‘Bagel’, 3, NOW() — INTERVAL ‘3 day’ — INTERVAL ‘1 hour’);
У нас есть три локации: HQ, Downtown, и 1st Street.
Также у нас есть два продукта: Coffee и Bagel (кофе и бублики). Продажи мы вносим с разными значениями sold_at, чтобы показать, сколько товаров было продано в разные дни и разное время.
У нас были продажи сегодня, вчера и позавчера.
Написание предложений GROUP BY
Предложение GROUP BY пишется очень просто. Мы используем ключевые слова GROUP BY и указываем поля, по которым должна происходить группировка:
SELECT … FROM sales GROUP BY location;
Этот простой запрос группирует данные таблицы sales по столбцу location.
Ну хорошо, мы их сгруппировали, но что нам поместить в наш SELECT?
Очевидно, что нам нужно сделать выборку локации. Мы группируем данные по этому столбцу и как минимум хотим увидеть имена созданных групп:
SELECT location FROM sales GROUP BY location;
Результатом будут три наши локации:
location ———— 1st Street HQ Downtown (3 rows)
Если мы посмотрим на необработанные данные нашей таблицы (SELECT * FROM sales;), мы увидим, что у нас есть четыре строки с локацией HQ, две строки с локацией Downtown и еще две — с локацией 1st Street:
product | location | price | sold_at ———+————+——-+—————————- Coffee | HQ | 2 | 2020-09-01 09:42:33.085995 Coffee | HQ | 2 | 2020-09-01 08:42:33.085995 Bagel | Downtown | 3 | 2020-09-01 07:42:33.085995 Coffee | Downtown | 2 | 2020-08-31 09:42:33.085995 Bagel | HQ | 2 | 2020-08-30 09:42:33.085995 Bagel | 1st Street | 3 | 2020-08-30 08:42:33.085995 Coffee | 1st Street | 2 | 2020-08-29 09:42:33.085995 Bagel | HQ | 3 | 2020-08-29 08:42:33.085995 (8 rows)
Группируя данные по столбцу location, наша база данных берет эти входные строки и определяет среди них уникальные локации. Эти уникальные локации служат в качестве «групп».
А как насчет остальных столбцов таблицы?
Если мы попробуем выбрать столбец product, по которому мы не делали группировку,
SELECT location, product FROM sales GROUP BY location;
мы получим вот такую ошибку:
ERROR: column «sales.product» must appear in the GROUP BY clause or be used in an aggregate function
Проблема в том, что мы взяли восемь строк и попытались втиснуть их в три.
Мы не можем просто возвращать оставшиеся столбцы, как обычно, потому что раньше у нас было восемь строк, а теперь их только три.
Что делать с оставшимися пятью строками данных? Какие данные из восьми строк должны быть отображены в трех строках?
На эти вопросы нет четкого и ясного ответа.
Чтобы использовать остальные данные таблицы, мы должны выделить данные из оставшихся столбцов в наши три локационные группы.
Это означает, что мы должны агрегировать эти данные или осуществить какие-то вычисления, чтобы получить некую итоговую информацию об оставшихся данных.
Агрегатные функции (COUNT, SUM, AVG)
Если мы решили сгруппировать данные, мы можем агрегировать данные оставшихся столбцов. например, мы можем посчитать число строк в каждой группе, суммировать отдельные значения в группе или вывести некое среднее значение (тоже по группе).
Для начала давайте найдем количество продаж по каждой локации.
Поскольку каждая запись в таблице sales это запись об одной продаже, число продаж по локации будет равно числу строк в каждой группе (при группировке по локациям).
Чтобы получить нужный результат, нам нужно применить агрегатную функцию COUNT() — так мы вычислим количество строк в каждой группе.
SELECT location, COUNT(*) AS number_of_sales FROM sales GROUP BY location;
Мы используем COUNT(*), чтобы считать все входящие строки в группе.
(COUNT() также работает с выражениями, но при этом имеет несколько другое поведение).
Вот как база данный выполняет наш запрос:
- FROM sales — Сначала получи все записи из таблицы sales.
- GROUP BY location — Затем определи уникальные группы при группировке по локации (т. е. уникальные локации).
- SELECT … — Наконец, выбери имя локации и посчитай число строк в этой группе.
Чтобы сделать вывод более читабельным, мы даем числу строк псевдоним — при помощи AS number_of_sales. Выглядит это так:
location | number_of_sales ————+—————— 1st Street | 2 HQ | 4 Downtown | 2 (3 rows)
Локация 1st Street имеет две продажи, HQ — четыре, а Downtown — две.
Как видно, здесь мы взяли данные столбца, по которому не делали группировку, и из восьми отдельных строк вычленили полезную итоговую информацию по каждой локации, а именно — число продаж.
SUM
Вместо подсчета числа строк в группе мы могли бы суммировать информацию по группе. Например, получить общее количество вырученных денег по каждой локации.
Для этого мы будем использовать функцию SUM():
SELECT location, SUM(price) AS total_revenue FROM sales GROUP BY location;
Вместо подсчета числа строк в каждой группе мы сложили количество долларов, полученных в результате каждой продажи, и вывели общий доход по локациям:
location | total_revenue ————+————— 1st Street | 5 HQ | 9 Downtown | 5 (3 rows)
AVG
Функция AVG() позволяет находить среднее значение (AVG от Average — среднее). Давайте найдем среднюю сумму выручки по локациям. Для этого просто заменим функцию SUM() на функцию AVG():
SELECT location, AVG(price) AS average_revenue_per_sale FROM sales GROUP BY location;
Работа с несколькими группами
Пока что мы работали с одной группировкой — по локациям. Что, если нам нужно разбить полученные группы на подгруппы?
Вспомните пример сценария, приведенный в начале статьи, с группировкой людей по цвету глаз и стране происхождения. Давайте попробуем найти число продаж каждого продукта в каждой отдельной локации (Например, сколько было продаж кофе, а сколько — бубликов на 1st Street, HQ и Downtown).
Для этого нам нужно добавить к нашему предложению GROUP BY второе группирующее условие:
SELECT … FROM sales GROUP BY location, product;
Добавив название еще одного столбца в наше предложение GROUP BY, мы разделили наши локационные группы на подгруппы по продуктам.
Поскольку теперь мы группируем также по столбцу product, мы можем вернуть результат при помощи нашего SELECT!
(Для облегчения чтения я добавил в запрос также предложения ORDER BY).
SELECT location, product FROM sales GROUP BY location, product ORDER BY location, product;
В результатах нашего нового группирования мы видим уникальные комбинации локаций и продуктов:
location | product ————+——— 1st Street | Bagel 1st Street | Coffee Downtown | Bagel Downtown | Coffee HQ | Bagel HQ | Coffee (6 rows)
Ну хорошо, у нас есть наши группы, а что мы будем делать с данными остальных столбцов?
Мы можем найти число продаж определенного продукта в каждой локации, используя все те же агрегатные функции:
SELECT location, product, COUNT(*) AS number_of_sales FROM sales GROUP BY location, product ORDER BY location, product; location | product | number_of_sales ————+———+—————— 1st Street | Bagel | 1 1st Street | Coffee | 1 Downtown | Bagel | 1 Downtown | Coffee | 1 HQ | Bagel | 2 HQ | Coffee | 2 (6 rows)
(Задание «со звездочкой»: найдите общую выручку (сумму) за каждый продукт в каждой локации).

Синтаксис GROUP BY
SELECT column_name(s) FROM table_name WHERE condition GROUP BY column_name(s) ORDER BY column_name(s);
Пример SQL GROUP BY
В следующем выражении SQL указано количество пользователей в каждой стране:
Пример:
SELECT COUNT(use_id), country FROM users GROUP BY country;
В следующем SQL-заявлении указано количество пользователей в каждой стране, отсортированных по высоким и низким:
Пример:
SELECT COUNT(user_id), country FROM users GROUP BY country ORDER BY COUNT(user_id) DESC;
GROUP BY с JOIN
В следующем выражении SQL указано количество заказов, отправленных каждой службой доставки:
Пример:
SELECT delivery.name, COUNT(invoice.delivery_id) AS orders FROM invoice LEFT JOIN delivery ON invoice.delivery_id = delivery.delivery_id GROUP BY name;
Группируем данные с помощью запроса group by
И в самом начале давайте разберем синтаксис group by, т.е. где писать данную конструкцию:
Синтаксис:
Select агрегатные функции
From источник
Where Условия отбора
Group by поля группировки
Having Условия по агрегатным функциям
Order by поля сортировки
Теперь если нам необходимо просуммировать все денежные средства того или иного сотрудника без использования группировки мы пошлем вот такой запрос:
SELECT SUM(summa)as summa FROM test_table WHERE name=’Иванов’
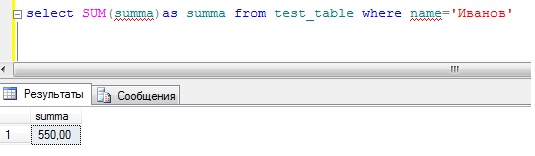
А если нужно просуммировать другого сотрудника, то мы просто меняем условие. Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
SELECT SUM(summa)as summa, name FROM test_table GROUP BY name
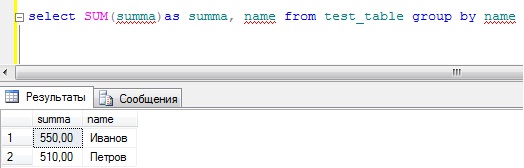
Как Вы заметили, мы не пишем никаких условий, и у нас отображаются сразу все сотрудники с просуммированным количеством денежных средств, что более наглядно.
Примечание!Сразу отмечу то, что, сколько полей мы пишем в запросе (т.е. поля группировки), помимо агрегатных функций, столько же полей мы пишем в конструкции group by. В нашем примере мы выводим одно поле, поэтому в group by мы указали только одно поле (name), если бы мы выводили несколько полей, то их все пришлось бы указывать в конструкции group by (в последующих примерах Вы это увидите).
Также можно использовать и другие функции, например, подсчитать сколько раз поступали денежные средства тому или иному сотруднику с общей суммой поступивших средств. Для этого мы кроме функции sum будем еще использовать функцию count.
SELECT SUM(summa)as [Всего денежных средств], COUNT(*) as [Количество поступлений], Name [Сотрудник] FROM test_table GROUP BY name
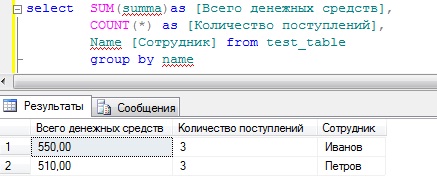
Но допустим для начальства этого недостаточно, они еще просят, просуммировать также, но еще с группировкой по признаку, т.е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
SELECT SUM(summa)as [Всего денежных средств], COUNT(*) as [Количество поступлений], Name [Сотрудник] , Priz [Источник] FROM test_table GROUP BY name, priz ORDER BY name
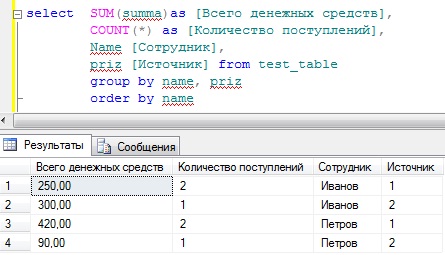
Теперь у нас все отображается, т.е. сколько денег поступило сотруднику, сколько раз, а также из какого источника.
А сейчас для закрепления давайте напишем еще более сложный запрос с группировкой, но еще добавим названия этого источника, так как согласитесь по идентификаторам признака не понятно из какого источника поступили средства. Для этого мы используем конструкцию case.
SELECT SUM(summa) AS [Всего денежных средств], COUNT(*) AS [Количество поступлений], Name [Сотрудник], CASE WHEN priz = 1 then ‘Оклад’ WHEN priz = 2 then ‘Премия’ ELSE ‘Без источника’ END AS [Источник] FROM test_table GROUP BY name, priz ORDER BY name
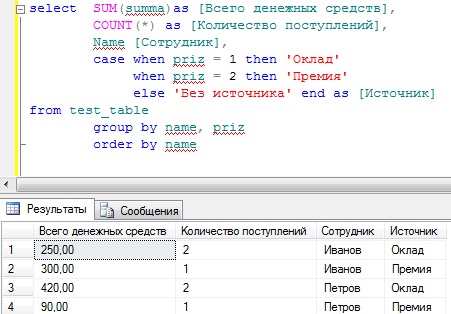
Вот теперь все достаточно наглядно и не так уж сложно, даже для начинающих.
Также давайте затронем условия по итоговым результатам агрегатных функций (having). Другими словами, мы добавляем условие не по отбору самих строк, а уже на итоговое значение функций, в нашем случае это sum или count. Например, нам нужно вывести все то же самое, но только тех, у которых «всего денежных средств» больше 200. Для этого добавим условие having:
SELECT SUM(summa)as [Всего денежных средств], COUNT(*) as [Количество поступлений], Name [Сотрудник], CASE WHEN priz = 1 then ‘Оклад’ WHEN priz = 2 then ‘Премия’ ELSE ‘Без источника’ END AS [Источник] FROM test_table GROUP BY name, priz —группируем HAVING SUM(summa) > 200 —отбираем ORDER BY name — сортируем
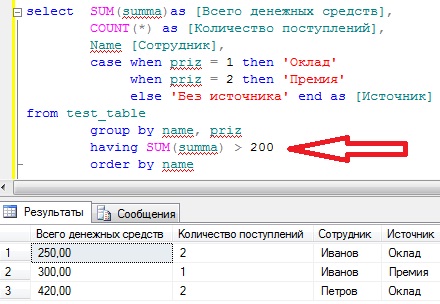
Теперь у нас вывелись все значения sum(summa), которые больше 200, все просто.
Использование конструкции GROUP BY с операцией ROLLUP
Как с помощью конструкции GROUP BY получать промежуточные итоговые значения (subtotals), уже было показано. За счет использования конструкции GROUP BY с операцией ROLLUP, однако, можно получать как промежуточные итоговые, так и общие суммарные (totals) значения и, следовательно, генерировать промежуточные агрегатные значения на любом уровне. Другими словами, операция ROLLUP позволяет получать агрегатные значения для каждой группы на отдельных уровнях. Промежуточные итоговые строки и конечные суммарные строки называются суперагрегатными строками (superaggregate rows).
В листинге ниже приведен пример применения конструкции GROUP BY с операцией ROLLUP.
SQL> SELECT Year,Country,SUM(Sales) AS Sales FROM Company_Sales GROUP BY ROLLUP (Year,Country); YEAR COUNTRY SALES ——— ——— ——- 1997 France 3990 1997 USA 13090 1997 17080 1998 France 4310 1998 USA 13900 1998 18210 1999 France 4570 1999 USA 14670 1999 19240 54530 /* Так выглядит конечное суммарное значение */ SQL>
Использование конструкции GROUP BY с операцией CUBE
Операцию CUBE можно считать расширением операции ROLLUP, поскольку она помогает расширять стандартные возможности конструкции GROUP BY в Oracle. Она вычисляет все возможные варианты промежуточных итоговых значений в операции GROUP BY. В предыдущем примере операция ROLLUP вернула промежуточные итоговые значения по годам. За счет использования операции CUBE можно получить итоговые значения не только по годам, но и по всей стране. Ниже приведен простой пример:
SQL> SELECT department_id, job_id, SUM(salary) 2 FROM employees 3 GROUP BY CUBE (department_id, job_id); DEPARTMENT_ID JOB_ID SUM(SALARY) ————- ——— ———— 10 AD_ASST 44000 20 MK_MAN 130000 20 MK_REP 60000 30 PU_MAN 110000 30 PU_CLERK 139000 . . . SQL>
Использование конструкции GROUP BY с операцией GROUPING
Как было показано ранее, операция ROLLUP позволяет получать суперагрегатные промежуточные и суммарные итоговые данные. Операция GROUPING в конструкции GROUP BY помогает проводить различие между столбцами с суперагрегатными промежуточными и суммарными итоговыми данными и прочими данными в строках.
Использование конструкции GROUP BY с операцией GROUPING SETS
Операция GROUPING SETS позволяет распределять множество наборов столбцов по группам при вычислении агрегатных показателей вроде сумм. Ниже приведен пример, демонстрирующий применение этой операции для вычисления агрегатных показателей с их последующим распределением по трем таким группам: (year, region, item), (year, item) и (region, item). Операция GROUPING SETS устраняет необходимость в использовании неэффективных операций UNION ALL.
SQL> SELECT year, region, item, sum(sales) FROM regional_salesitem GROUP BY GROUPING SETS (( year, region, item), (year, item), (region, item));
Использование конструкции GROUP BY с операцией HAVING
Операция HAVING позволяет ограничивать или исключать результаты операции GROUP BY, т.е., по сути, накладывать на результирующий набор GROUP BY условие WHERE. В следующем примере операция HAVING ограничивает результаты запроса только теми отделами, в которых максимальная зарплата превышает 20 000:
SQL> SELECT department_id, max(salary) 2 FROM employees 3 GROUP BY department_id 4* HAVING MAX(salary)>20000; DEPARTMENT_ID MAX(SALARY) ————- ———— 90 24000 SQL>
Группировка с агрегатными функциями
Агрегатные функции COUNT, SUM, AVG, MAX, MIN служат для вычисления соответствующего агрегатного значения ко всему набору строк, для которых некоторый столбец — общий.
Пример 4. Вывести количество выданных книг каждого автора. Запрос будет следующим:
SELECT Author, COUNT(*) AS InUse FROMBookinuseGROUP BY Author
Результатом выполнения запроса будет следующая таблица:
| Author | InUse |
| NULL | 1 |
| Гоголь | 1 |
| Ильф и Петров | 1 |
| Маяковский | 1 |
| Пастернак | 2 |
| Пушкин | 3 |
| Толстой | 3 |
| Чехов | 5 |
Пример 5. Вывести количество книг, выданных каждому пользователю. Запрос будет следующим:
SELECT Customer_ID, COUNT(*) AS InUse FROMBookinuseGROUP BY Customer_ID
Результатом выполнения запроса будет следующая таблица:
| User_ID | InUse |
| 18 | 1 |
| 31 | 3 |
| 47 | 4 |
| 65 | 2 |
| 120 | 3 |
| 205 | 3 |
.
Обновление агрегатных функций
Часто — когда вы работаете с базой данных — вы не хотите видеть фактические данные в базе данных. Вместо этого вам может потребоваться информация о данных. Например, вы можете узнать количество уникальных продуктов, которые продаёт ваш бизнес, или максимальный балл в таблице лидеров.
В SQL есть несколько встроенных функций, которые позволяют получить эту информацию. Они называются агрегатными функциями.
Например, предположим, что вы хотите узнать, сколько сотрудников являются торговыми партнёрами, вы можете использовать функцию COUNT. Функция COUNT подсчитывает и возвращает количество строк, соответствующих определённому набору критериев. Другие агрегатные функции включают SUM, AVG, MIN и MAX.
Когда следует использовать GROUP BY в SQL?
Предложение GROUP BY необходимо только тогда, когда вы хотите получить больше информации, чем-то, что возвращает агрегатная функция. Мы обсуждали это чуть раньше.
Если вы хотите узнать количество ваших клиентов, вам нужно всего лишь выполнить обычный запрос. Вот пример запроса, который вернёт эту информацию:
SELECT COUNT(name) FROM customers;
Наш запрос группирует результат и возвращает:
| считать |
| 7 |
(1 ряд)
Если вы хотите узнать, сколько клиентов входит в каждый из ваших планов лояльности, вам нужно будет использовать оператор GROUP BY. Вот пример запроса, который может получить список планов лояльности и количество клиентов по каждому плану:
SELECT loyalty_plan, COUNT(loyalty_plan)
FROM customers
GROUP BY loyalty_plan;
Наш запрос собирает данные. Затем наш запрос возвращает:
| loyalty_plan | считать |
| Золото | 1 |
| Никто | 3 |
| Серебро | 1 |
| Бронза | 2 |
(4 ряда)
SQL Group By по нескольким столбцам
Если бы мы хотели, мы могли бы выполнить GROUP BY для нескольких столбцов. Например, предположим, что мы хотели получить список сотрудников с определёнными должностями в каждом филиале. Мы могли бы получить эти данные, используя следующий запрос:
SELECT branch, title, COUNT(title)
FROM employees
GROUP BY branch, title;
Наш набор результатов запроса показывает:
Читайте также: Массив PostgreSQL в строку
| ответвляться | заглавие | считать |
| Стэмфорд | Сотрудник по продажам | 1 |
| Олбани | Вице-президент по продажам | 1 |
| Сан-Франциско | Сотрудник по продажам | 1 |
| Сан-Франциско | Старший специалист по продажам | 1 |
| Олбани | Директор по маркетингу | 1 |
| Бостон | Сотрудник по продажам | 2 |
(6 рядов)
Наш запрос создаёт список титулов, которыми владеет каждый сотрудник. Мы видим количество людей, обладающих этим титулом. Наши данные сгруппированы по отраслям, в которых работает каждый сотрудник, и их должностям.
- https://techrocks.ru/2020/09/24/sql-group-by-tutorial/
- https://unetway.com/tutorial/sql-zaavlenie-group-by
- https://info-comp.ru/obucheniest/368-transact-sql-group-by.html
- https://oracle-patches.com/oracle/develop/%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D0%B8-%D0%B3%D1%80%D1%83%D0%BF%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B8-group-by-%D0%B2-%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D0%B0%D1%85-sql-%D0%BA-%D0%B1%D0%B0%D0%B7%D0%B5-%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85-orqcle
- https://function-x.ru/sql_group_by.html
- https://bestprogrammer.ru/baza-dannyh/sql-group-by-polnoe-rukovodstvo-2