Содержание
- 1 Описание оконных функций
- 2 Два типа программирования: наборы и курсоры с итеративным проходом
- 3 Недостатки альтернатив оконным функциям
- 4 Оконные функции
- 5 Синтаксис оконной функции
- 6 MySQL. Список оконных функций
- 7 Оконные функции T-SQL и производительность
- 8 Предложение OVER и сортировка
- 9 Рамки (FRAME)
- 10 Агрегаты окна
- 11 Сравнение производительности
- 12 Заключение
Описание оконных функций
Оконная функция применяется к набору строк. Окно — стандартный термин SQL, служащий для описания контекста в котором работает функция. Для указания окна в SQL используется предложение OVER. Вот пример запроса:
USE TSQL2012; SELECT orderid, orderdate, val, RANK() OVER(ORDER BY val DESC) AS ‘rank’ FROM Sales.OrderValues ORDER BY ‘rank’;
Предложение OVER определяет окно (window), или точный набор строк по отношению к текущей строке, указание об упорядочении (если нужно) и другие элементы. Отсутствуют элементы, которые ограничивают набор строк в окне — как в данном примере, потому что набор строк окна является окончательным набором для запроса.
Если быть более точным, то окно представляет собой набор строк, или отношение, предоставляемые как входные данные этапа обработки логического запроса, в котором определено это окно. Но пока такое определение не совсем понятно. Поэтому для упрощения будем говорить об окончательном наборе результатов запроса — более подробное объяснение я дам чуть позже.
Упорядочение естественным образом необходимо для целей ранжирования. В данном примере оно основано на столбце val и обеспечивает ранжирование по убыванию.
В примере мы применили функцию RANK. Эта функция рассчитывает ранг текущей строки в определенном наборе строк в соответствии с порядком сортировки. При сортировке по убыванию, как в данном случае, ранг строки определяется на единицу больше числа строк в соответствующем наборе, у которых место в сортировке выше, чем у текущей строки.
Выберем одну из строк в результатах примера запроса, например с рангом 5. Этот ранг определен как 5, потому что в соответствии с заданным порядком сортировки (по убыванию val) в окончательном наборе результатов есть четыре строки, у которых значение атрибута val больше текущего значения (11188,40), а ранг определяется, как число этих строк плюс один.
Но самый важный нюанс заключается в том, что предложение OVER определяет окно функции по отношению к текущей строке. Это верно по отношению ко всем строкам набора результатов запроса. Иначе говоря, в каждой строке предложение OVER определяет окно независимо от остальных строк. Это очень важная концепция, и требуется определенное время на ее осознание. Освоив ее, вы приблизитесь к настоящему пониманию принципов работы с окнами, а также поймете всю ее глубину. Если пока вам это говорит немного, до времени не беспокойтесь — я вывалил все это скопом перед вами только для затравки.
Поддержка оконных функций в SQL описана в стандарте SQL:1999, где они назвались «OLAP functions». С того времени в каждой новой редакции поддержка оконных функций только укреплялась. Я имею в виду редакции SQL:2003, SQL:2008 и SQL:2011. В последнем стандарте SQL предусмотрена очень широкая поддержка оконных функций — нужно ли других доказательств, что в комитете стандартизации верят в них и, по-видимому, стандарт будет расширяться за счет увеличения числа оконных функций и сопутствующей функциональности.
Документы стандартов можно приобрести в организации ISO или ANSI. Например, по следующему URL-адресу можно приобрести документ фонда ANSI описанием стандарта SQL:2011, в котором описаны конструкции языка.
В стандарте SQL предусмотрена поддержка нескольких типов оконных функций: агрегатные, ранжирующие, аналитические (или распределения) и сдвига. Но надо не забывать, что окна — это принцип, поэтому в следующих редакциях стандарта могут появиться новые типы.
В агрегатных оконных функциях вы найдете привычные функции агрегирования, такие как SUM, COUNT, MIN, МАХ и другие, однако вы, скорее всего, привыкли к использованию их в контексте групп запросов. Функция агрегирования должна работать на наборе, который определен групповым запросом или определением окна. В SQL Server 2005 была реализована частичная поддержка оконных функций, а в SQL Server 2012 эта функциональность была расширена.
Реализованы следующие функции ранжирования: RANK, DENSE_RANK, ROW_NUMBER и NTILE. В стандарте первая и вторая пары функций относятся к разным категориям, и позже я объясню, почему. Я предпочитаю объединять эту четверку функций в одну категорию для простоты — точно так же, как это делается в официальной документации по SQL Server. В SQL Server 2005 эти четыре функции ранжирования уже обладают полной функциональностью.
К аналитическим функциям относятся PERCENT_RANK, CUME_DIST, PERCENTILE_CONT и PERCENTILE_DISC. Поддержка этих функций появилась в SQL Server 2012.
К функциям сдвига относятся LAG, LEAD, FIRST_VALUE, LAST, VALUE и NTH_VALUE. Поддержка эти функций также появилась в SQL Server 2012. Поддержки функции NTH_VALUE в SQL Server нет, и SQL Server 2012 не исключение.
Ниже рассказывается о назначении, целях и особенностях работы различных функций.
При освоении любой новой идеи, устройства или инструмента приходится преодолевать определенный барьер, даже если новинка проще в установке и использовании. Новое всегда дается нелегко. Поэтому если вы не знакомы с оконными функциями и анализируете, стоит ли тратить время на их изучение и применение, вот вам несколько аргументов «за»:
-
Оконные функции позволяют решать множество задач извлечения данных. Я бы сказал, что эту возможность сложно переоценить. Как я уже говорил, сейчас я использую оконные функции в большинстве ситуаций, когда нужно запрашивать данные. После рассказа о принципах работы и оптимизации функций будут показаны примеры практического их применения. Но чтобы вы уже сейчас понимали, как их можно использовать, скажу, что средствами оконных функций можно решать следующие задачи:
-
Разбиение на страницы.
-
Устранение дублирования данных.
-
Возвращение первых n строк в каждой группе.
-
Вычисление нарастающих итогов.
-
Выполнение операций в интервалах, например в интервалах упаковки, а также вычисление максимального числа параллельных сеансов.
-
Нахождение пробелов и диапазонов.
-
Вычисление процентилей.
-
Вычисление режима распределения.
-
Иерархии сортировки.
-
Сведение.
-
Определение новизны.
-
-
Я занимаюсь созданием SQL-запросов уже почти десять лет и на протяжении последних нескольких лет активно использую оконные функции. Могу сказать, что на освоение оконных функций требуется определенное время, но во многих случая оконные функции оказываются проще и более «интуитивными», чем обычные методы.
-
Оконные функции хорошо поддаются оптимизации.
Декларативный язык и оптимизация
Вас наверное удивит, почему в таком декларативном языке, как SQL, где вы просто заявляете, что хотите получить, а не описываете, как получить искомое, две формы одного и того же запроса — одна с оконными функциями, а другая без — дают разную производительность. Как так происходит, что в одной реализации SQL, такой как SQL Server, с собственным диалектом T-SQL, СУБД не всегда «догадывается», что две формы практически идентичны, и не создает одинаковые планы выполнения.
Для этого есть несколько причин. Для начала, оптимизатор SQL Server не идеален. Не поймите меня неправильно — оптимизатор SQL Server это настоящее чудо, если говорить о том, какие сложные задачи он решает. Но в нем невозможно реализовать все возможные правила. Это во-первых, а во-вторых, у оптимизатора есть очень ограниченное время на выполнение оптимизации — он мог бы тратить больше времени на оптимизацию, но надо понимать, что это время должно компенсироваться ускорением выполнения запроса.
Иногда ситуация доходит до абсурда: с одной стороны план, не учитывающий все возможные планы, но обеспечивающий выполнение запроса за несколько секунд, создается за несколько миллисекунд, а с другой — на определение плана, учитывающего все варианты и обеспечивающего сокращение времени выполнения запроса на несколько секунд может потребоваться год или даже больше.
Как видите, с практической точки зрения у оптимизатора очень ограниченное время на оптимизацию. На основании определенных параметров, в числе которых размер используемых в запросе таблиц, SQL Server определяет два значения: первое — стоимость удовлетворительного плана, а другое — максимально возможное время, которое можно потратить на оптимизацию. При достижении любого из этих значений SQL Server использует наилучший определенный на тот момент времени план выполнения.
Структура оконных функций такова, что они часто лучше поддаются оптимизации, чем другие методы решения тех же задач.
Из всего сказанного вы должны вынести следующее: чтобы перейти на использование оконных функций, нужно приложить определенные осознанные усилия, потому что это новая концепция, к которой надо привыкнуть. Но после этого использовать оконные функции становится просто и интуитивно понятно — вспомните о том, каким сложным вам казалось освоение гаджетов, без которых вы сейчас не представляете себе свою жизнь.
Два типа программирования: наборы и курсоры с итеративным проходом
Часто решения на основе T-SQL для запроса данных делят на два вида: основанные на наборах или на курсорах с итеративным проходом. Разработчики на T-SQL соглашаются, что нужно использовать первый подход, но курсоры все еще используются во многих решениях. В связи с этим возникает несколько интересных вопросов. Почему наборы считаются предпочтительнее? И если они рекомендованы к использованию, то почему многие разработчики используют итеративный подход? Что мешает людям использовать рекомендуемый подход?
Чтобы разобраться в этом, нужно понять основы T-SQL, что на самом деле представляет собой основанный на наборах подход. Если это сделать, то вы поймете, что для большинства людей наборы недостаточно интуитивно понятны, а логику итераций понять легче. Все дело в том, что разрыв между итеративным и основанным на наборах типами мышления довольно велик. Его можно сократить, но это непросто. Именно на этом этапе важную роль могут сыграть оконные функции. Я считаю их замечательным инструментом, способным закрыть разрыв между этими двумя подходами и обеспечить более гладкий переход к мышлению в терминах наборов.
Поэтому сначала объясню, что представляет собой основанный на наборах подход к решению задач получения данных средствами T-SQL. T-SQL является диалектом стандартного языка SQL (стандартов как ISO, так и ANSI). SQL основан (или является попыткой реализации) на базе реляционной модели, которая представляет собой математическую модель управления данными, изначально сформулированными и предложенными Е.Ф. Коддом в конце 1960-х.
Реляционная модель основана на двух математических принципах: теории множеств и логике предикатов. Многие аспекты компьютерных вычислений основаны на интуиции, при этом они очень быстро меняются — так быстро, что иногда кажется, что ты сам похож на кота, который гоняется за своим хвостом. Реляционная модель является островом в мире компьютерных вычислений, потому что основана на существенно более надежном основании — на математике. Некоторые считают математику истиной в последней инстанции. Строгие математические основания обеспечивают надежность и стабильность реляционной модели. Она развивается, но не так быстро, как другие области компьютерных вычислений. Вот уже несколько десятилетий реляционная модель оставалась незыблемой и сейчас она лежит в основе ведущих платформ баз данных, которые называют реляционными системами управления базами данных (РСУБД).
SQL представляет собой попытку создания языка, основанного на реляционной модели. SQL неидеален и, честно говоря, в ряде нюансов отклоняется от реляционной модели, но вместе с тем он предоставляет достаточно средств, чтобы человек, понимающий реляционную модель, мог использовать реляционные возможности средствами SQL. Этот язык — бесспорный ведущий де-факто язык современных РСУБД.
Однако, как я уже говорил, реляционное мышление во многих отношениях не интуитивно понятно. Отчасти сложность научиться мыслить в реляционных терминах заключается в фундаментальной разнице между итеративным и основанном на наборах подходах. Это особенно сложно дается тем, кто привык работать с процедурными языками программирования, в которых взаимодействие с данными в файлах осуществляется последовательно, как демонстрирует следующий псевдокод:
open file fetch first record while not end of file begin process record fetch next record end
Данные в файлах (или, если быть точнее, в файлах с индексированным последовательным доступом, или ISAM-файлах) хранятся в определенном порядке. И вы гарантировано можете получать записи из файла именно в таком порядке. Также записи можно получать по одной за раз. Поэтому вы привыкаете, что доступ к данным осуществляется именно так: по порядку и по одной записи за раз. Это похоже на работу с курсором в T-SQL. По этой причине для разработчиков с навыками процедурного программирования использование курсоров или других итеративных механизмов соответствует их опыту и представляется логичным способом работы с данными.
Реляционный, основанный на наборах подход к работе с данными фундаментально отличается от подобных навыков. Чтобы лучше понять его начнем с определения набора, или множества, принадлежащего создателю теории множеств Георгу Кантору: «Под «множеством» мы понимаем соединение в некое целое М определённых хорошо различимых предметов m нашего созерцания или нашего мышления (которые будут называться «элементами» множества М)».
Это очень емкое определение набора — чтобы сформулировать эту мысль мне бы пришлось потратить много времени. Но для целей нашей дискуссии я сосредоточусь на двух аспектах — один сформулирован в определении явно, а второй — неявно:
Целое
Заметьте, как используется термин целое. Набор надо воспринимать и работать с ним как с единым целым. К набору надо относиться как к единому целому, не различая отдельных его элементов. При итеративной обработке этот принцип нарушается, потому что с записями файла или курсора работают последовательно и по одной.
Таблица в SQL представляет (хотя и не совсем удачно) реляцию в терминах реляционной модели. При взаимодействии с таблицами с использованием основанных на наборах запросов вы работаете с таблицами как целым в отличие от работы с отдельными строками (кортежами отношений) — как в смысле формулировки декларативного запроса SQL, так и в смысле мысленного отношения к этой операции. Такой способ мышления очень многим дается нелегко.
Порядок
Заметьте, что нигде в определении набора не упоминается порядок элементов. Этому есть серьезная причина — среди элементов набора нет никакого порядка. Это еще одна особенность, на привыкание к которой требуется время. В файлах и курсорах элементы всегда расположены в определенном порядке, и при получении записей по одной за раз можно рассчитывать на сохранение такого порядка.
В таблице нет никакого порядка строк, потому что таблица представляет собой набор. Те, кто не понимают этого, часто путают логический уровень модели данных и язык с физическим уровнем реализации. Они предполагают, что если в таблице есть определенный индекс, неявно гарантируется, что при запросе таблицы доступ к данным всегда будет осуществляться в порядке индекса. Иногда даже на этом предположении строят логику решения. Ясно, что SQL Server не гарантирует такого порядка. Например, единственный способ гарантировать определенный порядок строк в результате запроса — добавить в запрос сортировку ORDER BY. И если добавить такое предложение, то нужно понимать, что результат не будет реляционным, потому что он гарантировано упорядочен.
Если вам нужно создавать запросы SQL и вы хотите понимать этот язык, вам нужно мыслить в терминах наборов. В такой ситуации оконные функции могут поспособствовать заполнению пробела между итеративным (одна строка за раз в определенном порядке) и основанным на наборах типами мышления (отношение к набору как к единому целому при отсутствии порядка). Переходу от старого к новому мышлению способствует оригинальная структура оконных функций.
Кстати оконные функции поддерживают предложение ORDER BY, которое используется в ситуациях, когда нужно задать порядок. Но указание порядка в такой функции не означает, что она нарушает реляционные принципы. Входные данные запроса являются реляционными, то есть без всякого упорядочения, впрочем, как и выходные данные, в которых тоже нет гарантии порядка. В условиях операции задано упорядочение — только поэтому в результирующем отношении присутствует атрибут результата. Нет гарантии, что результирующие строки будут возвращены оконной функцией в том же порядке.
В сущности, в разных оконных функциях в одном запросе могут задаваться разные варианты упорядочения. Подобное упорядочение не имеет ничего общего, по крайней мере концептуально, с упорядочением в представлении в запросе.
На рисунке ниже я пытаюсь показать, что как входные, так и выходные данные оконной функции являются реляционными, несмотря на то, что в определении оконной функции задано упорядочивание. Овалами и разным порядком строк во входных и выходных данных я пытаюсь выразить тот факт, что порядок строк не имеет значения
Есть еще одна особенность оконных функций, которая помогает постепенно перейти от итеративного мышления к мышлению в терминах наборов. Иногда при объяснении новой темы учителям приходится прибегать к определенной доли «лжи». Представьте, что вы преподаватель, который понимает, что сознание студентов пока не готово к освоению определенной идеи, если ее сразу излагать в полном объеме. Иногда лучше начать объяснение идеи в более простых и не совсем корректных терминах — такой подход позволяет подготовить студентов к освоению материала. Какое-то время спустя, когда студенты «созреют» для понимания «правды», можно переходить к более глубокому и более корректному изложению материала.
Именно такая ситуация возникает с пониманием того, как в принципе вычисляются оконные функции. Есть базовый вариант объяснения этого материала, он не совсем корректный, но позволяет добиться нужного результата! В этом варианте используется подход, основанный на обработке по одной строке из упорядоченного списка. В дальнейшем используется глубокий, более принципиально корректный способ объяснения этого принципа, но перед его изложением надо подготовить читателя. Во втором способе используется подход на основе наборов.
Чтобы понять, что я имею в виду, посмотрите на следующий запрос:
SELECT orderid, orderdate, val, RANK() OVER(ORDER BY val DESC) AS ‘rank’ FROM Sales.OrderValues;
сортировать строки по значению val итеративный проход строк for each строка if текущая строка является первой в секции, вернуть 1 if значение val равно предыдущему значению val, вернуть предыдущий ранг else вернуть текущее число обработанных строк
Хотя такой способ мышления дает правильный результат, он не совсем корректный. Честно говоря, моя задача усложняется еще и тем, что такой процесс очень похож на то, как вычисление ранга физически реализовано в SQL Server. Но на данном этапе моя цель не физическая реализация, а концептуальный уровень — язык и логическая модель. Под «неправильным мышлением» я имею в виду, что концептуально, с точки зрения языка, вычисление мыслится иначе — в терминах наборов, а не итераций. Помните, что язык никак не связан с конкретной физической реализацией в ядре СУБД. Задача физического уровня — определить, как выполнить логический запрос, и максимально быстро вернуть правильный результат.
А теперь я попытаюсь объяснить, что подразумеваю под более глубоким, правильным пониманием трактовки оконных функций в языке. Функция логически определяет для каждой строки в результирующем наборе запроса отдельное, независимое окно. В отсутствие ограничений в определении окна вначале каждое окно состоит из набора всех строк результирующего набора запроса. В определение окна можно добавлять дополнительные элементы (например, секционирование, кадрирование и т.п. — об этом я расскажу чуть позже), которые дополнительно ограничивают набор строк в каждом окне.
Концептуально, с точки зрения каждой оконной функции и строки в результирующем наборе запроса предложение OVER создает для них отдельные окна. В нашем запросе мы никак не ограничивали определение окна, а только задали упорядочение. Поэтому в нашем случае все окна состоят из всех строк в результирующем наборе. И они сосуществуют в одно время. И в каждом ранг рассчитывается как увеличенное на единицу число строк, у которых значение атрибута val больше, чем у текущего значения.
Вы наверное понимаете, что многим проще думать в базовых терминах то есть считать, что данные упорядочены и процесс итеративно проходит по строкам, по одной за раз. И это нормально, что вы начинаете с оконных функций, потому что вам нужно писать запросы правильно, по крайней мере простые. Со временем вы можете постепенно переходить к более глубокому пониманию концептуального построения оконных функций и начинать мыслить в терминах наборов.
Недостатки альтернатив оконным функциям
У оконных функций есть ряд преимуществ перед альтернативными, более традиционными способами выполнения аналогичных задач, например перед групповыми, вложенными и другими запросам. Сейчас я приведу несколько простых примеров. Есть другие отличия, помимо тех, которые я здесь демонстрирую, но о них пока рано еще говорить.
Я начну с традиционных групповых запросов. Они дают новую информацию в виде агрегатов, но кое-что при этом теряется — детали.
При группировке данных вы вынуждены применять все вычисления в контексте группы. Но что, если нужно выполнить вычисления, которые предусматривают использование как детальных данных, так и агрегатов. Представьте, что надо запросить представление Sales.OrderValues с заказами и вычислить размер каждого заказа как процент от общей суммы по клиенту, а также разницу со средним размером заказа для соответствующего клиента. Текущий размер заказа является подробной информацией, а общие и средние значения представляют собой агрегаты. Если сгруппировать данные по клиентам, теряется доступ к значениям отдельных заказов.
Один из способов решения этой задачи средствами групповых запросов заключается в создании запроса, который группирует данные по клиентам, определении табличного выражения на основе этого запроса, а затем соединение табличного выражения с базовой таблицей для сопоставления подробных данных с агрегатами. Вот выражение, реализующее эту логику:
use TSQL2012; WITH Aggregates AS ( SELECT custid, SUM(val) AS sumval, AVG(val) AS avgval FROM Sales.OrderValues GROUP BY custid ) SELECT O.orderid, O.custid, O.val, CAST(100. * O.val / A.sumval AS NUMERIC(5, 2)) AS pctcust, O.val — A.avgval AS diffcust FROM Sales.OrderValues AS O JOIN Aggregates AS A ON O.custid = A.custid;
А теперь представьте себе, что также надо вычислить размер заказа как процент от общей суммы заказов, а также как отклонение от среднего по всем клиентам. Для решения этой задачи придется добавить еще одно табличное выражение:
use TSQL2012; WITH CustAggregates AS ( SELECT custid, SUM(val) AS sumval, AVG(val) AS avgval FROM Sales.OrderValues GROUP BY custid ), GrandAggregates AS ( SELECT SUM(val) AS sumval, AVG(val) AS avgval FROM Sales.OrderValues ) SELECT O.orderid, O.custid, O.val, CAST(100. * O.val / CA.sumval AS NUMERIC(5, 2)) AS pctcust, O.val — CA.avgval AS diffcust, CAST(100. * O.val / GA.sumval AS NUMERIC(5, 2)) AS pctall, O.val — GA.avgval AS diffall FROM Sales.OrderValues AS O JOIN CustAggregates AS CA ON O.custid = CA.custid CROSS JOIN GrandAggregates AS GA;
Как видите, запрос становится все сложнее и сложнее, включая все больше табличных выражений и операций соединения.
Иначе задачу можно решить, воспользовавшись отдельными вложенными запросами для каждого вычисления. Вот альтернативное решение на основе вложенных запросов:
use TSQL2012; — Вложенные запросы с подробными данными и агрегатами по отдельным клиентам SELECT orderid, custid, val, CAST(100. * val / (SELECT SUM(O2.val) FROM Sales.OrderValues AS O2 WHERE O2.custid = O1.custid) AS NUMERIC(5, 2)) AS pctcust, val — (SELECT AVG(O2.val) FROM Sales.OrderValues AS O2 WHERE O2.custid = O1.custid) AS diffcust FROM Sales.OrderValues AS O1; — Вложенные запросы с подробными данными и агрегатами по всем и отдельным клиентам SELECT orderid, custid, val, CAST(100. * val / (SELECT SUM(O2.val) FROM Sales.OrderValues AS O2 WHERE O2.custid = O1.custid) AS NUMERIC(5, 2)) AS pctcust, val — (SELECT AVG(O2.val) FROM Sales.OrderValues AS O2 WHERE O2.custid = O1.custid) AS diffcust, CAST(100. * val / (SELECT SUM(O2.val) FROM Sales.OrderValues AS O2) AS NUMERIC(5, 2)) AS pctall, val — (SELECT AVG(O2.val) FROM Sales.OrderValues AS O2) AS diffall FROM Sales.OrderValues AS O1;
С таким подходом есть две основные проблемы. Во-первых, код слишком пространен и сложен. А, во-вторых, в настоящее время оптимизатор SQL Server не распознает случаи, когда нескольким вложенным запросам нужен доступ к одному и тому же набору строк, поэтому в каждом вложенном запросе будет выполняться отдельный доступ к данным. Это означает, что чем больше вложенных запросов, тем больше раз будут читаться одни и те же данные. В отличие от предыдущей проблемы, это проблема не языка, а конкретной реализации вложенных запросов в SQL Server.
Как вы помните, идея оконной функции заключается в определении окна, или набора, строк, на основе которого работает функция. Предполагается, что функции агрегации применяются к наборам строк, поэтому принцип окон должен хорошо подойти для решения таких задач в качестве альтернативы групп запросов и вложенных запросов. После вычисления агрегатной оконной функции детальная информация не теряется. Для определения окна функции можно применять предложение OVER.
Например, чтобы вычислить сумму всех значений в результирующем наборе запроса, можно просто воспользоваться следующим:
SUM(val) OVER()
Если не ограничить окно (в скобках пусто), исходной точкой считается результирующий набор запроса.
Чтобы вычислить сумму всех значений результирующего набора, у которых идентификатор клиента (customer ID) такой же, как в текущей строке, используйте возможности секционирования в оконных функциях (о нем я расскажу попозже) и выполните секционирование окна по custid следующим образом:
SUM(val) OVER(PARTITION BY custid)
Заметьте, что термин секционирование подразумевает фильтрацию, а не группировку.
Вот как с помощью оконных функций создать запрос, обеспечивающий подробные данные и агрегаты по клиентам, возвращая в процентах размер заказа среди всех заказов клиента, а также отклонение от среднего размера заказа:
use TSQL2012; SELECT orderid, custid, val, CAST(100. * val / SUM(val) OVER(PARTITION BY custid) AS NUMERIC(5, 2)) AS pctcust, val — AVG(val) OVER(PARTITION BY custid) AS diffcust FROM Sales.OrderValues;
А вот еще один запрос, в котором дополнительно добавляется размер заказа как процент от общей суммы заказов и процент отклонения от общего среднего по всем заказам:
SELECT orderid, custid, val, CAST(100. * val / SUM(val) OVER(PARTITION BY custid) AS NUMERIC(5, 2)) AS pctcust, val — AVG(val) OVER(PARTITION BY custid) AS diffcust, CAST(100. * val / SUM(val) OVER() AS NUMERIC(5, 2)) AS pctall, val — AVG(val) OVER() AS diffall FROM Sales.OrderValues;
Заметьте, насколько проще и лаконичнее выглядит запрос с оконными функциями. Если говорить об оптимизации, то нужно сказать, что в оптимизаторе SQL Server предусмотрена логика обнаружения нескольких функций с одинаковым определением окна. Обнаружив такие функции, SQL Server читает необходимые данные только раз (независимо от типа операции чтения). Например, в последнем запросе SQL Server обратится раз к данным чтобы вычислить первые две функции (сумму и среднее, секционированные по custid), и еще раз — чтобы вычислить последние две функции (несекционированные сумму и среднее). Я продемонстрирую этот принцип оптимизации позже.
Другое преимущество оконных функций перед вложенными запросами заключается в том, что исходное окно до применения ограничений является результирующим набором запроса. Это означает, что это результирующий набор после применения табличных операторов (например, соединений) фильтров, групп и т.п. Этот результирующий набор — следствие того, на какой фазе логической обработки запроса вычисляются оконные функции.
С другой стороны, вложенный запрос начинает работу с нуля, а не с набора результатов внешнего запроса. Это означает, что если нужно, чтобы вложенный запрос работал с тем же набором, что и внешний запрос, в нем придется повторить все те же конструкции, что и во внешнем запросе. В качестве примера представьте, что нужно вычислить процент от суммы и отклонение от среднего только для заказов за 2007 год. При использовании оконных функций достаточно просто добавить в запрос один фильтр:
use TSQL2012; SELECT orderid, custid, val, CAST(100. * val / SUM(val) OVER(PARTITION BY custid) AS NUMERIC(5, 2)) AS pctcust, val — AVG(val) OVER(PARTITION BY custid) AS diffcust, CAST(100. * val / SUM(val) OVER() AS NUMERIC(5, 2)) AS pctall, val — AVG(val) OVER() AS diffall FROM Sales.OrderValues WHERE orderdate >= ‘20070101’ AND orderdate < ‘20080101’;
Исходной точкой всех оконных функций является набор после применения этого фильтра. А вот в решении с вложенными запросами приходится начинать все сначала — фильтр придется повторить во всех вложенных запросах:
use TSQL2012; SELECT orderid, custid, val, CAST(100. * val / (SELECT SUM(O2.val) FROM Sales.OrderValues AS O2 WHERE O2.custid = O1.custid AND orderdate >= ‘20070101’ AND orderdate < ‘20080101’) AS NUMERIC(5, 2)) AS pctcust, val — (SELECT AVG(O2.val) FROM Sales.OrderValues AS O2 WHERE O2.custid = O1.custid AND orderdate >= ‘20070101’ AND orderdate < ‘20080101’) AS diffcust, CAST(100. * val / (SELECT SUM(O2.val) FROM Sales.OrderValues AS O2 WHERE orderdate >= ‘20070101’ AND orderdate < ‘20080101’) AS NUMERIC(5, 2)) AS pctall, val — (SELECT AVG(O2.val) FROM Sales.OrderValues AS O2 WHERE orderdate >= ‘20070101’ AND orderdate < ‘20080101’) AS diffall FROM Sales.OrderValues AS O1 WHERE orderdate >= ‘20070101’ AND orderdate < ‘20080101’;
Ясно, что можно воспользоваться обходными решениями, например предварительно определить обобщенное табличное выражение (CTE) на основе запроса, выполняющего фильтрацию, после чего сослаться на это CTE из внешнего запроса и вложенных запросов. Однако я хочу сказать, что с оконными функциями не нужно никаких ухищрений, потому что они работают на основе результата запроса.
Как говорилось ранее, оконные функции хорошо поддаются оптимизации, а альтернативные решения часто практически не поддаются оптимизации. Естественно, что есть прямо противоположные ситуации.
Оконные функции
Оконные функции определены в стандарте ISOSQL. В СУБД семейства MS SQLServer предоставляются ранжирующие и статистические оконные функции. Окно — это набор строк, определяемый пользователем. Оконная функциявычисляет значение для каждой строки в результирующем наборе, полученном из окна.
Оконные функции могут использоваться для вычисления кумулятивных, скользящих и центрированных агрегатов. Они возвращают значение для каждой строки в таблице, которое зависит от других строк соответствующего окна. Они могут быть использованы только в предложениях SELECT и ORDER BY запроса. Как правило, оконные функции обеспечивают доступ к более чем одной строке таблицы без самосоединения.
Предложение OVER
Предложение OVER определяет секционирование и упорядочение набора строк до применения соответствующей оконной функции. В качестве оконных функций используются агрегатные и статистические ( SUM, AVG, MAX, MIN, COUNT ), ранжирующие функции. Каждая из ранжирующих функций ROW_NUMBER, DENSE_RANK, RANK и NTILE задействует предложение OVER (см. сл. раздел настоящей лекции).
Синтаксис:
- Для ранжирующих оконных функций< OVER_CLAUSE > ::= OVER ( [PARTITION BY value_expression, … [n] ]
) - Для агрегатных функций< OVER_CLAUSE > ::= OVER ( [PARTITION BY value_expression, … [n] ]
PARTITION BY разделяет результирующий набор на секции. Оконная функция применяется к каждой секции отдельно, и вычисление начинается заново для каждой секции. Если это предложение опущено, функция интерпретирует все результирующее множество как одну группу.
value_expression указывает столбец, по которому секционируется набор строк, произведенный соответствующим предложением FROM. Аргумент value_expression может ссылаться только на столбцы, доступные через предложение FROM. Аргумент value_expression не может ссылаться на выражения или псевдонимы в списке выбора. Выражение value_expression может быть выражением столбца, скалярным вложенным запросом, скалярной функцией или пользовательской переменной.
Предложение ORDER BY задает порядок для ранжирующей оконной функции. Если предложение ORDER BY используется в контексте ранжирующей оконной функции, оно может ссылаться только на столбцы, доступные через предложение FROM. Указывать положение имени или псевдонима столбца в списке выборки с помощью целого числа нельзя. Предложение ORDER BY не может работать со статистическими оконными функциями.
В одном запросе с одним предложением FROM может использоваться несколько статистических или ранжирующих оконных функций. Однако предложение OVER для каждой функции может применять свое секционирование и упорядочение. Предложение OVER не может работать со статистической функциейCHECKSUM.
Семантика NULL-значений оконных функций соответствует семантике NULL-значений агрегатных функций SQL.
Статистические оконные функции
Покажем на примере, как используются статистические оконные функции.
Пример. 16.4. Статистические оконные функции.
Пусть в ХД имеется таблица фактов «Позиции счетов» (OrderDetail), содержащая номер позиции (OrderID), идентификатор товара (ProductID), количество товара (OrderQt) и стоимость товара (Price). Физическая структура таблицы приведена на рис. 23.4.
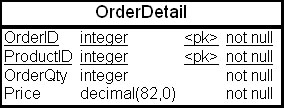
Рис. 23.4. Физическая структура таблицы фактов «Финансы» (Finance)
Пусть необходимо для двух позиций счетов 43659 и 43664 посчитать для каждого проданного товара общее количество проданного товара, среднее количество каждого проданного товара, минимальное и максимальное количество проданного товара.
Следующий запрос решает поставленную задачу с использованием оконных функций.
SELECT OrderID, ProductID, OrderQty ,SUM(OrderQty) OVER(PARTITION BY OrderID) AS ‘Итого’ ,AVG(OrderQty) OVER(PARTITION BY OrderID) AS ‘Среднее’ ,COUNT(OrderQty) OVER(PARTITION BY OrderID) AS ‘Кол-во’ ,MIN(OrderQty) OVER(PARTITION BY OrderID) AS ‘Min’ ,MAX(OrderQty) OVER(PARTITION BY OrderID) AS ‘Max’ FROM OrderDetail WHERE OrderID IN(43659,43664); GO
Результат выполнения запроса приведен ниже.
Вывод 3.
| 43659 | 776 | 1 | 26 | 2 | 12 | 1 | 6 |
| 43659 | 777 | 3 | 26 | 2 | 12 | 1 | 6 |
| 43659 | 778 | 1 | 26 | 2 | 12 | 1 | 6 |
| 43659 | 771 | 1 | 26 | 2 | 12 | 1 | 6 |
| 43659 | 772 | 1 | 26 | 2 | 12 | 1 | 6 |
| 43664 | 772 | 1 | 14 | 1 | 8 | 1 | 4 |
| 43664 | 775 | 4 | 14 | 1 | 8 | 1 | 4 |
| 43664 | 714 | 1 | 14 | 1 | 8 | 1 | 4 |
Пусть руководство организации требует подсчитать процент проданного товара по позиции 43659. Следующий запрос с использованием оконных функций решает поставленную задачу.
SELECT OrderID, ProductID, OrderQty ,SUM(OrderQty) OVER(PARTITION BY OrderID) AS ‘Итого’ ,CAST(1. * OrderQty / SUM(OrderQty) OVER(PARTITION BY OrderID) *100 AS DECIMAL(5,2))AS ‘Процент проданного товара’ FROM OrderDetail WHERE OrderID = 43659;
Результат выполнения запроса приведен ниже.
Вывод 4.
| 43659 | 776 | 1 | 26 | 3.85 |
| 43659 | 777 | 3 | 26 | 11.54 |
| 43659 | 778 | 1 | 26 | 3.85 |
| 43659 | 771 | 1 | 26 | 3.85 |
| 43659 | 772 | 1 | 26 | 3.85 |
Как видно из рассмотренных примеров, использование предложения OVER является более эффективным, чем использование вложенных запросов. Применение оконных ранжирующих функций будет рассмотрено в следующем разделе.
Синтаксис оконной функции
Общий синтаксис вызова оконной функции следующий:
window_function_name(expression) OVER ( [partition_defintion] [order_definition] [frame_definition] )
В этом синтаксисе:
- Сначала укажите имя оконной функции, а затем выражение.
- Во-вторых, укажите предложение OVER, которое имеет три возможных элемента: определение раздела, определение порядка и определение фрейма.
Открывающая и закрывающая скобки после предложения OVER являются обязательными, даже без выражения, например:
window_function_name(expression) OVER()
Синтаксис partition_clause
partition_clause разбивает строки на части или перегородки. Два раздела разделены границей раздела.
Функция окна выполняется внутри разделов и повторно инициализируется при пересечении границы раздела.
Синтаксис partition_clause выглядит следующим образом:
PARTITION BY
Вы можете указать одно или несколько выражений в предложении PARTITION BY. Несколько выражений разделяются запятыми.
Синтаксис order_by_clause
order_by_clause имеет следующий синтаксис:
ORDER BY
Предложение ORDER BY определяет порядок упорядочения строк в разделе. Можно упорядочить данные внутри раздела по нескольким ключам, каждый ключ определяется выражением. Несколько выражений также разделяются запятыми.
Подобно этому предложению PARTITION BY, предложение ORDER BY также поддерживается всеми оконными функциями. Однако имеет смысл использовать предложение ORDER BY только для чувствительных к порядку оконных функций.
Синтаксис frame_clause
Фрейм является подмножеством текущего раздела. Чтобы определить подмножество, вы используете предложение frame следующим образом:
frame_unit {
Фрейм определяется относительно текущей строки, что позволяет фрейму перемещаться внутри раздела в зависимости от положения текущей строки в его разделе.
Единица фрейма определяет тип отношения между текущей строкой и строками фрейма. Это может быть ROWS или RANGE. Смещения текущей строки и строки кадра являются номерами строк, если единица кадра равна, ROWSи значениями строки является единица кадра RANGE.
frame_start и frame_between определяют границы фрейма.
frame_start cодержит одно из следующих действий:
- UNBOUNDED PRECEDING: рамка начинается с первого ряда раздела.
- N PRECEDING: физический N строк перед первой текущей строкой. N может быть буквальным числом или выражением, которое оценивается как число.
- CURRENT ROW: строка текущего расчета
frame_between выглядит следующим образом:
BETWEEN frame_boundary_1 AND frame_boundary_2
Каждый фрейм frame_boundary_1 и frame_boundary_2 может содержать одно из следующего:
- frame_start: как упоминалось ранее.
- UNBOUNDED FOLLOWING: фрейм заканчивается в последнем ряду раздела.
- N FOLLOWING: физический N строк после текущей строки.
Если вы не укажете frame_definition в предложении OVER, то MySQL по умолчанию использует следующий фрейм:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
MySQL. Список оконных функций
В следующей таблице показаны оконные функции в MySQL:
| CUME_DIST | Вычисляет совокупное распределение значения в наборе значений. |
| DENSE_RANK | Присваивает ранг каждой строке в своем разделе на основе предложения ORDER BY. Он присваивает одинаковый ранг строкам с одинаковыми значениями. Если две или более строки имеют одинаковый ранг, то в последовательности ранжированных значений не будет пробелов. |
| FIRST_VALUE | Возвращает значение указанного выражения относительно первой строки в рамке окна. |
| LAG | Возвращает значение N-й строки перед текущей строкой в разделе. Возвращает NULL, если предшествующей строки не существует. |
| LAST_VALUE | Возвращает значение указанного выражения относительно последней строки в рамке окна. |
| LEAD | Возвращает значение N-й строки после текущей строки в разделе. Возвращает NULL, если никакой последующей строки не существует. |
| NTH_VALUE | Возвращает значение аргумента из N-й строки рамки окна |
| NTILE | Распределяет строки для каждого раздела окна в указанное количество ранжированных групп. |
| PERCENT_RANK | Вычисляет процентильный ранг строки в разделе или наборе результатов |
| RANK | Аналогична функции DENSE_RANK() за исключением того, что в последовательности ранжированных значений есть пробелы, когда две или более строки имеют одинаковый ранг. |
| ROW_NUMBER | Назначает последовательное целое число каждой строке в своем разделе |
Оконные функции в MariaDB
Функции управления окнами были добавлены в стандарт ANSI/ISO SQL: 2003, а затем расширены в стандарте ANSI/ISO SQL: 2008. DB2, Oracle, Sybase, PostgreSQL и другие продукты имеют полные реализации в течение многих лет. Другие производители добавили поддержку оконных функций позже. Например, когда Microsoft представила оконные функции в SQL Server 2005, она включала лишь несколько функций, а именно ROW_NUMBER, RANK, NTILE и DENSE_RANK. Только в SQL Server 2012 был реализован полный спектр оконных функций.
После многочисленных желаний и запросов на функции для оконных функций они были наконец представлены в MariaDB 10.2.0. Теперь MariaDB включает в себя оконные функции, такие как ROW_NUMBER, RANK, DENSE_RANK, PERCENT_RANK, CUME_DIST, NTILE, COUNT, SUM, AVG, BIT_OR, BIT_AND и BIT_XOR.
Оконные функции T-SQL и производительность
Оконные функции упрощают написание многих запросов и зачастую обеспечивают лучшую производительность по сравнению со старыми методами. Например, использование функции LAG существенно лучше, чем применение самосоединения. Однако чтобы добиться лучшей производительности в целом, необходимо понимать концепции оконных функций, и то как они используют сортировку для получения результата.
Предложение OVER и сортировка
Имеется две конструкции в предложении OVER, которые могут привести к сортировке: ORDER BY и PARTITION BY. PARTITION BY поддерживается всеми оконными функциями, но не является обязательной. ORDER BY является обязательной для большинства функций. В зависимости от того, что вы пытаетесь выполнить, данные будут сортироваться в соответствии с предложением OVER, и это может являться узким местом производительности вашего запроса.
Например, вы хотите применить функцию ROW_NUMBER в порядке SalesOrderID. Результат будет отличаться от, скажем, применения функции в порядке убывания TotalDue:
USE AdventureWorks2017; —или другая версия, которая у вас установлена
GO
SELECT SalesOrderID,
TotalDue,
ROW_NUMBER() OVER(ORDER BY SalesOrderID) AS RowNum
FROM Sales.SalesOrderHeader;
SELECT SalesOrderID,
TotalDue,
ROW_NUMBER() OVER(ORDER BY TotalDue DESC) AS RowNum
FROM Sales.SalesOrderHeader;
Поскольку первый запрос использует кластерный ключ в опции ORDER BY, никакой сортировки не требуется.
План выполнения второго запроса содержит дорогую операцию сортировки.
ORDER BY в предложении OVER никак не связан с предложением ORDER BY для всего запроса. Следующий пример показывает, что происходит, если они отличаются:
SELECT SalesOrderID,
TotalDue,
ROW_NUMBER() OVER(ORDER BY TotalDue DESC) AS RowNum
FROM Sales.SalesOrderHeader
ORDER BY SalesOrderID;
Ключом кластерного индекса является SalesOrderID, однако строки сначала должны быть отсортированы по TotalDue в убывающем порядке, а затем снова по SalesOrderID. Взгляните на план:
Предложение PARTITION BY тоже может вызывать сортировку. Это подобно, хотя и не вполне точно, предложению GROUP BY в агрегирующих запросах. Следующий запрос нумерует строки для каждого клиента.
SELECT CustomerID,
SalesOrderID,
TotalDue,
ROW_NUMBER() OVER(PARTITION BY CustomerID ORDER BY SalesOrderID) AS RowNum
FROM Sales.SalesOrderHeader;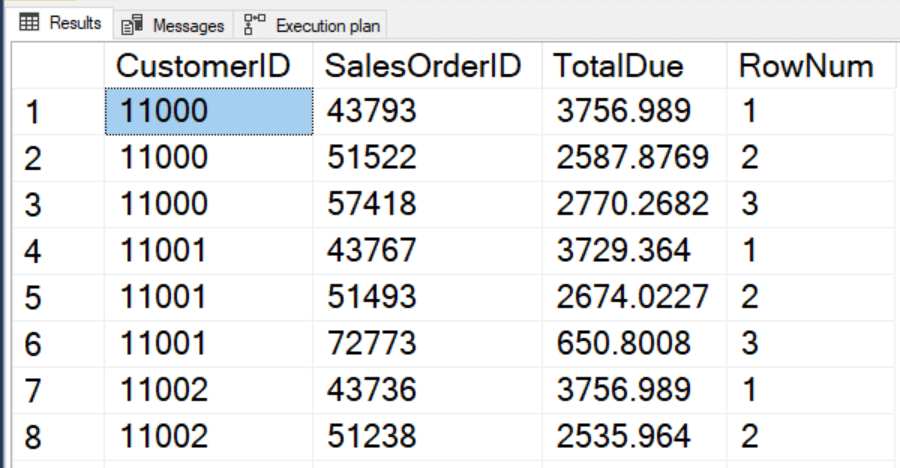
План выполнения показывает только одну сортировку по комбинации столбцов – CustomerID и SalesOrderID.
Одним из способов избежать падения производительности является создание индекса специально под предложение OVER. В своей книге Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions, Ицик Бен-Ган предлагает POC-индекс (POC – (P)ARTITION BY, (O)RDER BY, and (C)overing). Он рекомендует добавлять любые столбцы, используемые для фильтрации, перед столбцами PARTITION BY и ORDER BY в ключ индекса. Затем добавлять любые дополнительные столбцы, необходимые для создания покрывающего индекса, в качестве включенных столбцов. Как и всегда, следует выполнить тестирование, как такой индекс повлияет на ваш запрос и общую нагрузку. Разумеется, вы не можете добавлять индексы для каждого запроса, который пишете. Но если проблемы производительности вызывает конкретный запрос, который использует оконную функцию, важно принять во внимание этот совет.
Вот индекс, который улучшает предыдущий запрос:
CREATE NONCLUSTERED INDEX test ON Sales.SalesOrderHeader
(CustomerID, SalesOrderID)
INCLUDE (TotalDue);
Рамки (FRAME)
На мой взгляд, рамки представляются наиболее сложной для понимания концепцией при изучении оконных функций. Рамки требуются в случаях:
- Оконные агрегаты с ORDER BY, используемые для вычисления накопительных итогов, перемещающихся средних и т.д.
- FIRST_VALUE
- LAST_VALUE
К счастью, рамки требуются не всегда, однако, к сожалению, легко упустить их из виду, используя поведение по умолчанию. Рамка по умолчанию всегда RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW (диапазон от начала до текущей строки). Хотя вы будете получать правильные результаты, если предложение ORDER BY содержит уникальный столбец или комбинацию столбцов, вы увидите скачок производительности.
Вот пример, сравнивающий окно по умолчанию и правильное окно:
SET STATISTICS IO ON;
GO
SELECT CustomerID,
SalesOrderID,
TotalDue,
SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID) AS RunningTotal
FROM Sales.SalesOrderHeader;
SELECT CustomerID,
SalesOrderID,
TotalDue,
SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS RunningTotal
FROM Sales.SalesOrderHeader;
Результаты одинаковы, но производительность сильно разнится. К сожалению, план выполнения не скажет вам правды в этом случае. Он отводит каждому запросу по 50% ресурсов: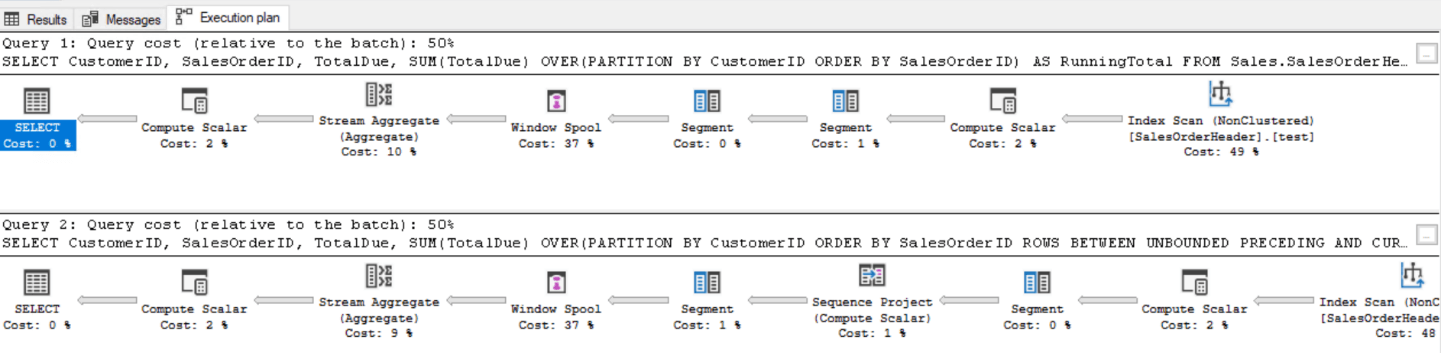
Если вы посмотрите статистику по вводу/выводу, то увидите разницу: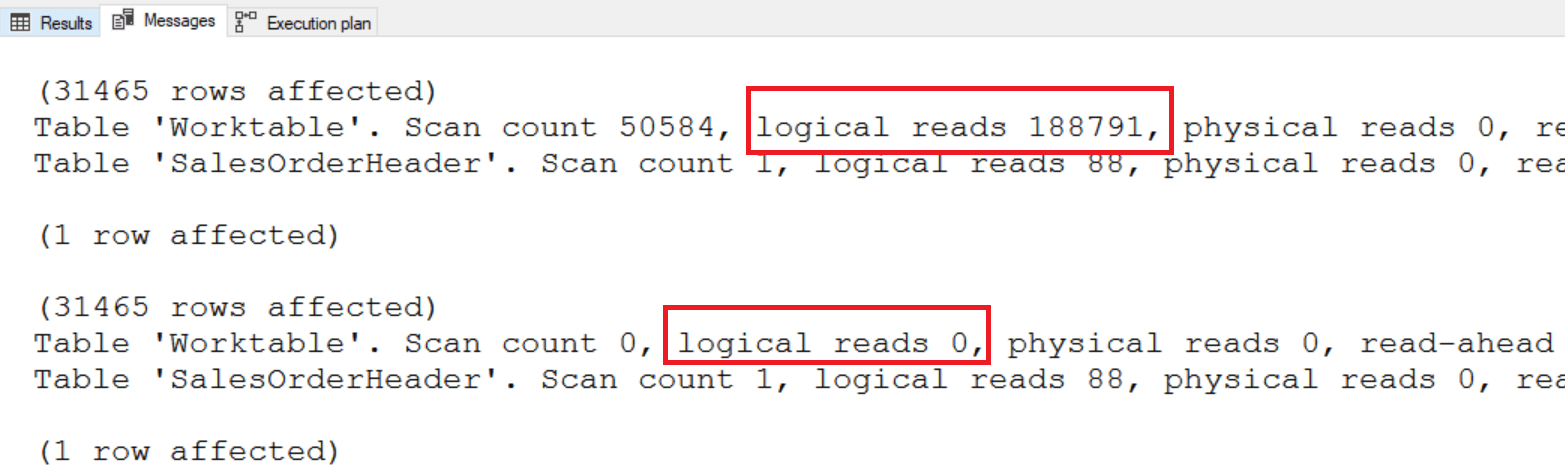
Использование правильной рамки окна даже более важно, если опция ORDER BY не уникальна или если вы используете LAST_VALUE. В данном примере в ORDER BY используется столбец OrderDate, а некоторые покупатели размещают более одного заказа в день. Если не задать рамки окна, или использовать RANGE, функция рассматривает совпадающие даты как часть одного и того же окна.
SELECT CustomerID,
SalesOrderID,
TotalDue,
OrderDate,
SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY OrderDate) AS RunningTotal,
SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY OrderDate
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS CorrectRunningTotal
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (‘11433′,’11078′,’18758’);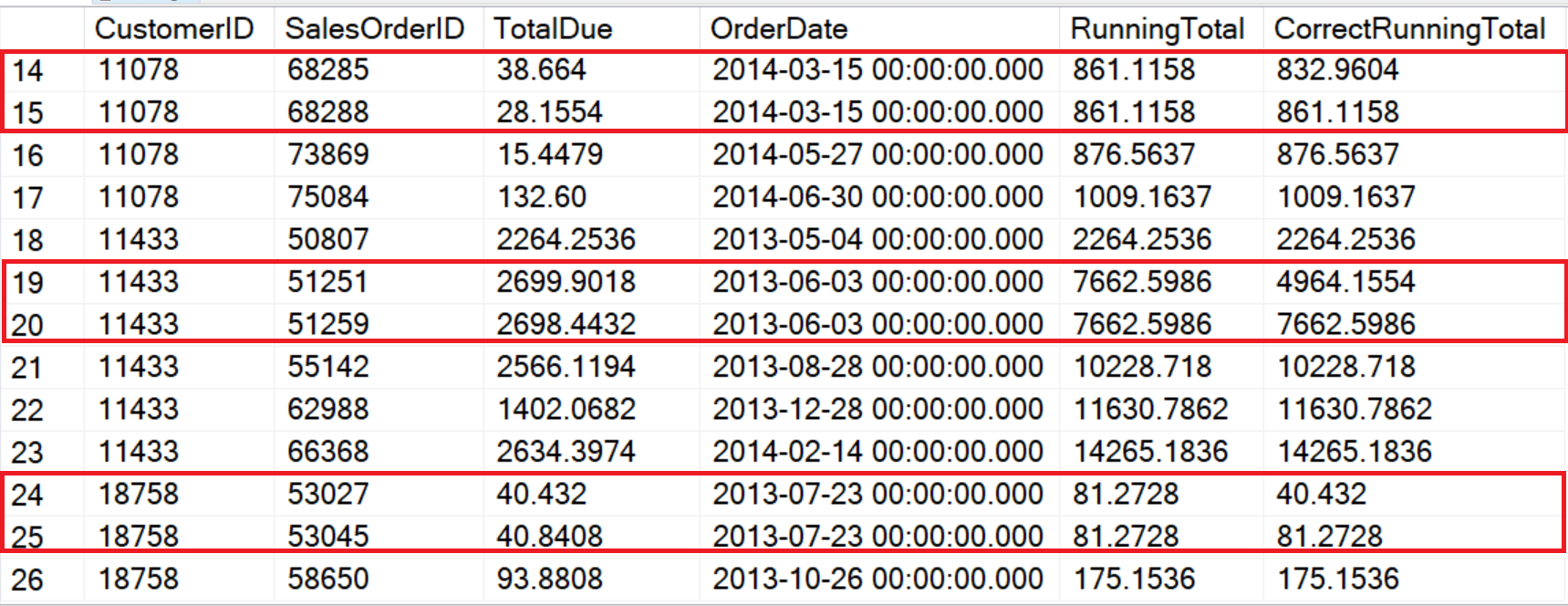
Причина несоответствия состоит в том, что RANGE видит данные логически, в то время как ROWS видит их позиционно. Существует 2 решения этой проблемы. Первое – это сделать опцию ORDER BY уникальной. Второй и более важный способ – всегда задавать рамку там, где она поддерживается.
Другая область, где рамки вызывают логические проблемы, связана с LAST_VALUE. LAST_VALUE возвращает выражение из последней строки рамки. Поскольку значение по умолчанию рамки (RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) простирается только до текущей строки, последняя строка рамки и есть строка, для которой выполняются вычисления. Вот пример:
SELECT CustomerID,
SalesOrderID,
TotalDue,
LAST_VALUE(SalesOrderID) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID) AS LastOrderID,
LAST_VALUE(SalesOrderID) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS CorrectLastOrderID
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, SalesOrderID;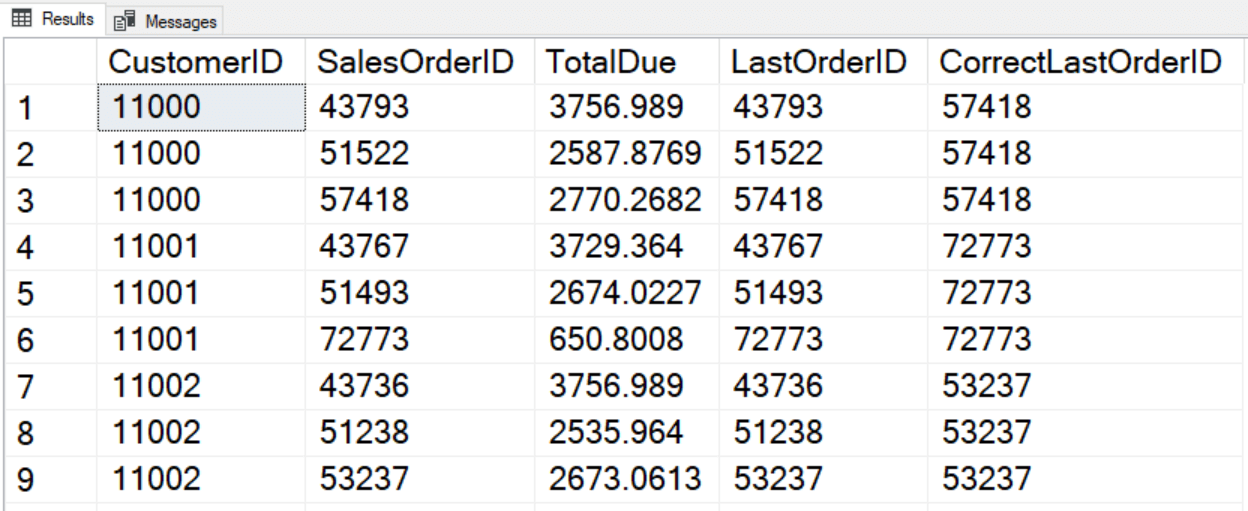
Агрегаты окна
Одной их полезнейших особенностей оконных функций является возможность добавлять агрегатные выражения в неагрегатные запросы. К сожалению, это часто плохо сказывается на производительности. Чтобы понять проблему, нужно посмотреть статистику ввода/вывода, где вы увидите большое число логических чтений. Если вам требуется вернуть значения с разной детализацией в одном запросе для большого числа строк, я советую использовать один из старых методов, например, общие табличные выражения (CTE), временные таблицы или даже переменные. Если возможно заранее вычислить агрегаты до использования оконных агрегатов, — это еще один способ. Вот пример, который демонстрирует разницу между оконным агрегатом и другим методом:
SELECT SalesOrderID,
TotalDue,
SUM(TotalDue) OVER() AS OverallTotal
FROM Sales.SalesOrderHeader
WHERE YEAR(OrderDate) =2013;
DECLARE @OverallTotal MONEY;
SELECT @OverallTotal = SUM(TotalDue)
FROM Sales.SalesOrderHeader
WHERE YEAR(OrderDate) = 2013;
SELECT SalesOrderID,
TotalDue,
@OverallTotal AS OverallTotal
FROM Sales.SalesOrderHeader AS SOH
WHERE YEAR(OrderDate) = 2013;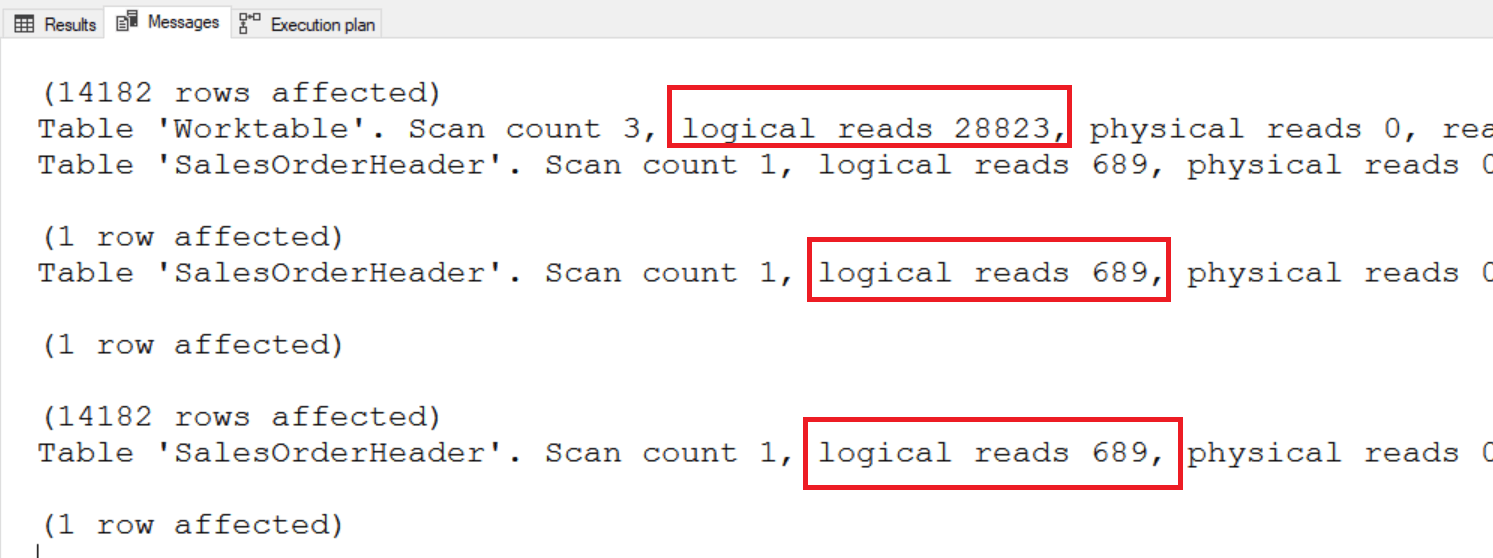
Первый запрос сканирует таблицу лишь один раз, однако он имеет 28823 логических чтений в рабочей таблице. Второй метод сканирует таблицу дважды, но ему не требуется рабочая таблица.
Следующий пример использует оконный агрегат, применяемый к агрегатному выражению:
SELECT YEAR(OrderDate) AS OrderYear,
SUM(TotalDue) AS YearTotal,
SUM(TotalDue)/
SUM(SUM(TotalDue)) OVER() * 100 AS PercentOfSales
FROM Sales.SalesOrderHeader
GROUP BY YEAR(OrderDate)
ORDER BY OrderYear;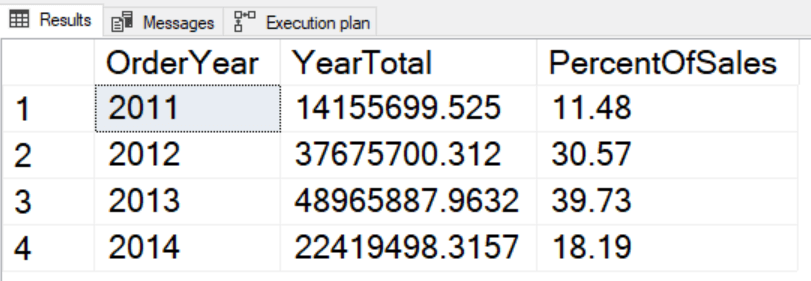
При использовании оконных функций в агрегирующем запросе, выражение должно следовать тем же правилам, что и предложения SELECT и ORDER BY. В данном случае оконная функция применяется к SUM(TotalDue). Это выглядит как вложенный агрегат, однако на самом деле оконная функция применяется к агрегатному выражению.
Поскольку данные были агрегированы до применения оконной функции, запрос демонстрирует хорошую производительность:
Существует более интересная вещь, знать о которой нужно, используя агрегатные функции. Если вы используете множественные выражения, у которых совпадает определение предложения OVER, вы не увидите дополнительного падения производительности.
Я советую использовать эту функциональность с осторожностью. Это весьма удобно, но не так хорошо масштабируется.
Сравнение производительности
До сих пор в примерах использовалась небольшая таблица Sales.SalesOrderHeader из базы данных AdventureWorks, и внимание уделялось плану выполнения и логическим чтениям. В реальной жизни ваших клиентов не беспокоит ни план выполнения, ни логические чтения; им важно насколько быстро выполняется запрос. Чтобы увидеть разницу во времени исполнения, я использую скрипт Адама Мачаника (Adam Machanic) с некоторыми изменениями.
Скрипт создает таблицу с именем bigTransactionHistory, содержащую свыше 30 миллионов строк. После выполнения скрипта Адама я создала еще две копии этой таблицы с 15 и 7,5 миллионами строк соответственно. Кроме того, я включила опцию Discard results after execution (Отбросить результаты после выполнения) в параметрах результатов запроса с тем, чтобы заполнение сетки не отражалось на времени выполнения. Я запускала тест три раза и чистила кэш буфера перед каждым запуском.
Ниже приводится скрипт для создания дополнительных тестовых таблиц:
SELECT TOP(50) Percent *
INTO mediumTransactionHistory
FROM bigTransactionHistory;
SELECT TOP(25) PERCENT *
INTO smallTransactionHistory
FROM bigTransactionHistory;
GO
ALTER TABLE mediumTransactionHistory
ALTER COLUMN TransactionID INT NOT NULL;
GO
ALTER TABLE mediumTransactionHistory
ADD CONSTRAINT pk_mediumTransactionHistory PRIMARY KEY (TransactionID);
GO
ALTER TABLE smallTransactionHistory
ALTER COLUMN TransactionID INT NOT NULL;
GO
ALTER TABLE smallTransactionHistory
ADD CONSTRAINT pk_smallTransactionHistory PRIMARY KEY (TransactionID);
GO
CREATE NONCLUSTERED INDEX IX_ProductId_TransactionDate
ON mediumTransactionHistory
(
ProductId,
TransactionDate
)
INCLUDE
(
Quantity,
ActualCost
ON smallTransactionHistory
(
ProductId,
TransactionDate
)
INCLUDE
(
Quantity,
ActualCost
- Решение на базе курсора
- Коррелирующий подзапрос
- Оконная функция с рамкой по умолчанию
- Оконная функция с ROWS
Я запускала тест на трех новых таблицах. Ниже приводятся результаты в виде графиков: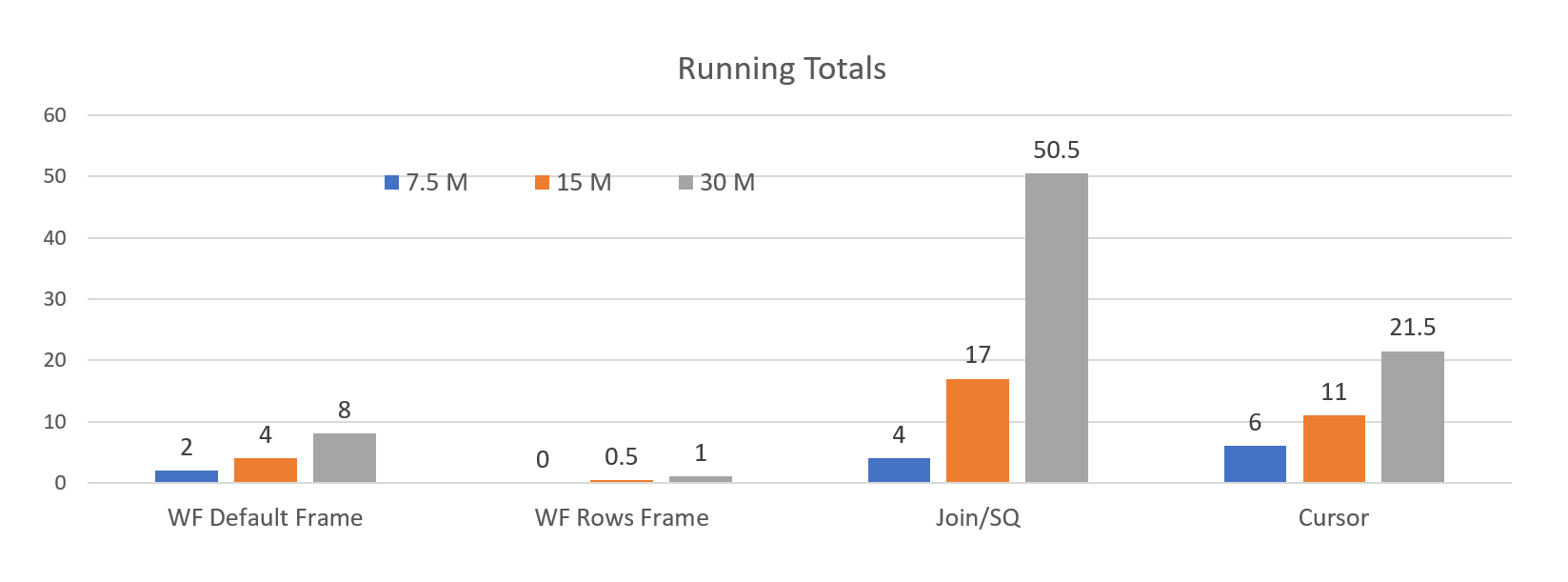
В случае с рамкой ROWS на таблице с 7,5 миллионом строк запросу на выполнение потребовалось меньше секунды. На таблице в 30 миллионов строк время запуска составило около минуты.
Вот запрос, использующий рамку ROWS, который выполнялся на таблице в 30 миллионов строк:
SELECT ProductID, SUM(ActualCost) OVER(PARTITION BY ProductID ORDER BY TransactionDate
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS RunningTotal
FROM bigTransactionHistory;
Я также проводила тесты, чтобы посмотреть, как оконные агрегаты ведут себя по сравнению с традиционными методами. В этом случае я просто использовала таблицу в 30 миллионов строк, но выполняла одно, два или три вычисления, используя одну и ту же степень детализации и, следовательно, одно и то же предложение OVER. Сравнивалась производительность оконных агрегатов с CTE и коррелирующим подзапросом.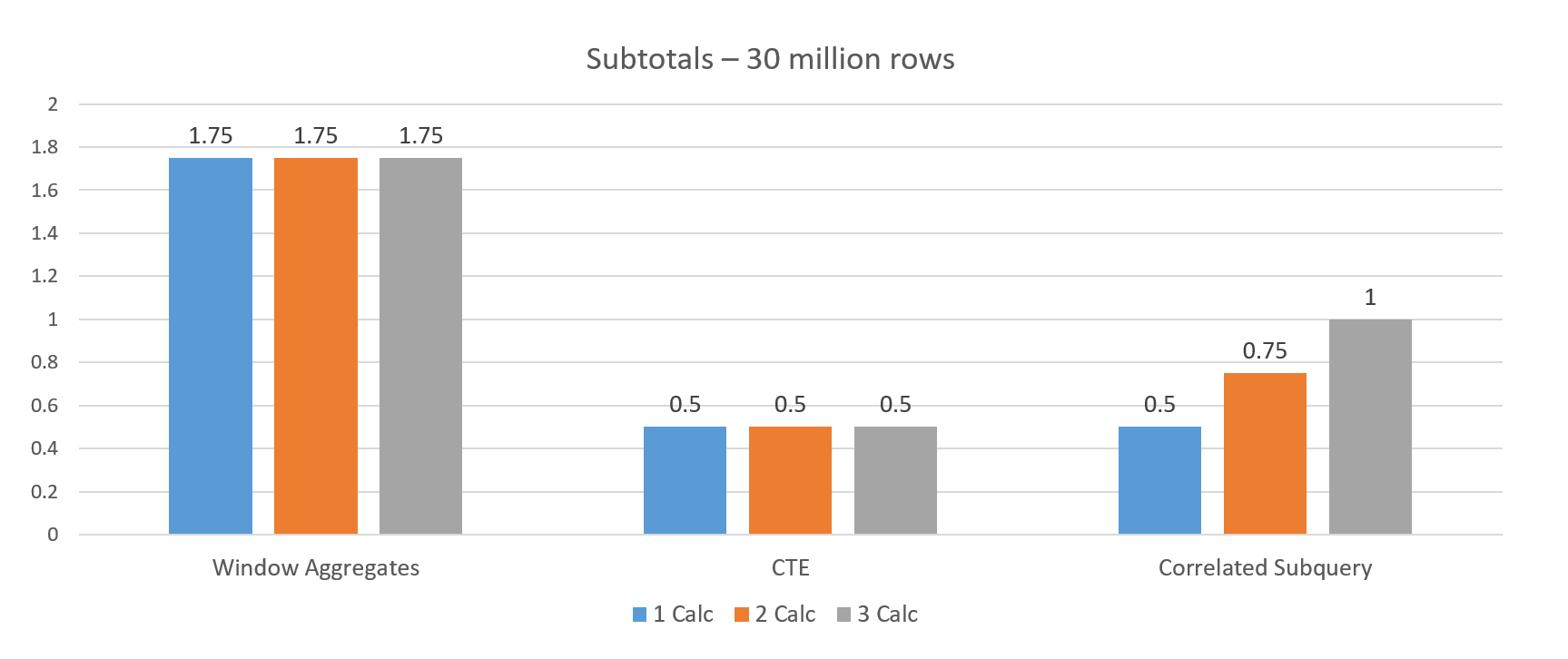
Производительность оконных агрегатов оказалась худшей – около 1,75 минут в каждом случае. CTE показал лучший результат при увеличении числа вычислений, поскольку таблица читалась только один раз для всех трех вычислений. Производительность коррелирующего подзапроса ухудшалась с увеличением числа вычислений, поскольку каждое вычисление должно было выполняться отдельно, что приводило к четырем обращениям к таблице.
Вот запрос-победитель:
WITH Calcs AS (
SELECT ProductID,
AVG(ActualCost) AS AvgCost,
MIN(ActualCost) AS MinCost,
MAX(ActualCost) AS MaxCost
FROM bigTransactionHistory
GROUP BY ProductID)
SELECT O.ProductID,
ActualCost,
AvgCost,
MinCost,
MaxCost
FROM bigTransactionHistory AS O
JOIN Calcs ON O.ProductID = Calcs.ProductID;
Заключение
Оконные функции T-SQL продвигались как средство значительного повышения производительности. На мой взгляд, они позволяют проще писать запросы. И вам следует их понимать, чтобы получить хорошую производительность. Индексирование имеет значение, но вы не можете создавать индекс для каждого запроса. Рамки сложнее понять, но это становится очень важным для больших таблиц.
- https://professorweb.ru/my/sql-server/window-functions/level1/1_1.php
- https://intuit.ru/studies/courses/599/455/lecture/10186?page=2
- https://andreyex.ru/bazy-dannyx/baza-dannyx-mysql/mysql-okonnye-funktsii/
- https://bloglinux.ru/3354-sravnenie-okonnyh-funkcij-i-cte-v-mysql-8-i-mariadb.html
- https://www.sql-ex.ru/blogs/?/Okonnye_funkcii__T-SQL_i_proizvoditelnost.html